สรุปสิ่งที่ได้จากการเรียน การเตรียมฝึกประสบการณ์วิชาชีพบริหารธุรกิจ
1. ได้ทักษะและความรู้จากวิทยากรแขนงต่าง
ซึ่งในการเรียนวิชาเตรียมฝึกประสบการณ์วิชาชีพบริหารธุรกิจ เเต่ละครั้งจะมีวิทยากรมาบรรยายความรู้
ให้ฟัง และจะต้องทดสอบทักษะด้านภาษาอังกฤษ และด้านไอที (คอมพิวเตอร์) เนื่องจากทุกการทดสอบสามารถนำความรู้ที่ได้มานั้นไปใช้ในการทำงานได้จริง ซึ่งการบรรยายทุกครั้งจะมีเเต่สิ่งที่เป็นประโยชน์ที่สามารถนำมาพัฒนาตนเองให้มีศักยภาพมากขึ้น
2. การตรงต่อเวลา
ในการเรียนเเต่ละครั้งเราต้องรับผิดชอบเรื่องเวลาด้วยเพราะต้องเข้าเรียนตรงเวลาเสมอ ถ้าเข้าไม่ทันก็จะขาดเรียนไป ทำให้เกิดปัญหาต่างๆไม่ว่าจะโดนตัดคะเเนน ไม่ได้รับความรู้ เป็นต้น ข้าพเจ้าคิดว่าอันดับเเรกของการทำงานจริงก็คือเราควรไปให้ตรงเวลาเพื่อป้องกันไม่ให้เกิดการผิดพลาดได้
3. การทำงานอย่างเป็นระบบ
ซึ่งในการทำงานทุกครั้งเราจะต้องประสานงานกันภายในห้องเเละภายในคณะไม่ว่าจะเป็นเรื่องอะไรก็แล้วเเต่ เช่น เรื่องการคุมสอบทักษะไอที การทำโครงการเตรียมฝึกประสบการณ์วิชาชีพ เป็นต้น ซึ่งเราจะต้องช่วยกันทำงานเพื่อให้เสร็จให้ทันเวลา
4. ความรับผิดชอบ
ซึ่งการทำงานที่ได้รับมอบหมายเเต่ละครั้ง จะต้องทำงานให้เสร็จลุล่วงทันเวลา
ในการเรียนวิชาเตรียมฝึกประสบการณ์วิชาชีพบริหารธุรกิจข้าพเจ้าคิดว่า ได้เรียนรู้สิ่งใหม่ๆหลายอย่างรวมถึงสิ่งที่ข้าพเจ้าไม่เคยได้รู้มาก่อน ได้รับประสบการณ์ฝึกวิชาชีพ แง่คิดต่าง จากวิทยากรที่มาบรรยายในเเต่ละเเขนง ข้อคิดดีๆอีกมากมายจากอาจารย์และวิทยากรทุกท่าน ซึ่งข้าพเจ้าคิดว่าข้าพเจ้าจะนำความรู้และทักษะที่ได้ฝึกมาพัฒนาตัวข้าพเจ้าเองทั้งในเวลาปัจจุบันและอนาคตก่อนที่จะทำงานจริงค่ะ
วันพุธที่ 14 ตุลาคม พ.ศ. 2552
วันเสาร์ที่ 19 กันยายน พ.ศ. 2552
DTS 11-16-09-2552
สรุป Searching
การค้นหาข้อมูล (searching)
แบ่งเป็น 2 ประเภท คือ
1.การค้นหาข้อมูลแบบภายใน
2.การค้นหาข้อมูลแบบภายนอก
การค้นหาแบบเรียงลำดับ (Linear search)
เป็นวิธีการค้นหาข้อมูลที่ง่ายและตรงไปตรงมาที่สุด การค้นหาทำได้โดยนำค่าหลักไปเปรียบเทียบกับข้อมูลทั้งหมดทีละตัวตั้งแต่ตัวแรกเรียงตามลำดับจนกว่าจะพบข้อมูลที่ต้องการ
หรือเปรียบเทียบไปจนถึงตัวสุดท้ายและพบว่าไม่มีข้อมูลนี้อยู่
ตัวอย่าง เช่น มีข้อมูลอยู่ 10 จำนวน ดังนี้
18 3 39 70 27 8 1 31 2 50
เมื่อต้องการค้นหาเลขจำนวนเต็ม 2 ให้นำไปเปรียบเทียบกับข้อมูลทีละตัว
เริ่มที่ตัวแรกคือ 18 ถ้าไม่ใช่ข้อมูลที่ต้องการให้ไปเปรียบเทียบกับข้อมูลตัวถัดไป
จนกว่าจะพบข้อมูลที่ต้องการก็หยุดค้น หรือค้นหาจนถึงข้อมูลตัวสุดท้ายแล้วยังไม่พบข้อมูล
ที่ต้องการก็สรุปได้ว่าไม่มีข้อมูลที่ต้องการ ในตัวอย่างนี้การค้นหา 2 ต้องมีการเปรียบเทียบกับค่าต่าง ๆ
ทั้งหมด 9 ครั้ง จึงจะพบข้อมูลที่ต้องการ
การค้นหาแบบเซนทินัล(Sentinel)
เป็นวิธีที่การค้นหาแบบเดียวกับวิธีการค้นหาแบบเชิงเส้นแต่ประสิทธิภาพดีกว่า
ตรงที่เปรียบเทียบน้อยครั้งกว่า วิธีการ คือ
1. เพิ่มขนาดของแถวลำดับ ที่ใช้เก็บข้อมูลอีก 1 ที่
2. นำข้อมูลที่จะใช้ค้นหาข้อมูลใน Array ไปฝากที่ต้นหรือ ท้าย Array
3. ตรวจสอบผลลัพธ์จากการหา โดยตรวจสอบจากตำแหน่งที่พบ ถ้าตำแหน่งที่พบมีค่าเท่ากับ n-1แสดงว่าหาไม่พบนอกนั้นถือว่าพบข้อมูลที่ค้าหา
การค้นหาแบบไบนารี (Binary Search)
เป็นวิธีการค้นหาข้อมูลที่รวดเร็วกว่าการค้นหาแบบเรียงลำดับ แต่วิธีนี้ใช้ได้ในกรณีที่ข้อมูลถูกจัดเก็บแบบเรียงลำดับเรียบร้อยแล้ว โดยอาจจะเรียงลำดับจากน้อยไปมากหรือจากมากไปน้อย การค้นหาข้อมูลด้วยวิธีนี้ ในการเปรียบเทียบแต่ละครั้งสามารถลดจำนวนข้อมูลที่ต้องเปรียบเทียบได้คราวละประมาณครึ่งหนี่งของที่เหลือ
โดยการค้นหาข้อมูลแบบทวิภาคเริ่มต้นด้วยการหาว่าตำแหน่งกึ่งกลางของ ข้อมูลทั้งหมดอยู่ที่ตำแหน่งใด
เนื่องจากข้อมูลทั้งหมดมีการเรียงลำดับค่า ถ้าเรียงจากน้อยไปมาก ข้อมูลที่ตำแหน่งกึ่งกลางจะแบ่งข้อมูลเป็น 2 ส่วน ส่วนแรกเป็นข้อมูลที่มีค่าน้อยกว่าค่าที่ตำแหน่งกึ่งกลาง และส่วนที่ 2 เป็นข้อมูลที่มีค่ามากกว่าค่าที่ตำแหน่ง กึ่งกลาง
สูตรในการค้นหาตำแหน่งตัวเเทน คือ
mid = (low+high)/2mid คือ ตำแหน่งกลาง
low คือ ตำแหน่งต้นแถวลำดับ
high คือ ตำแหน่งท้ายของแถวลำดับ
การค้นหาข้อมูล (searching)
แบ่งเป็น 2 ประเภท คือ
1.การค้นหาข้อมูลแบบภายใน
2.การค้นหาข้อมูลแบบภายนอก
การค้นหาแบบเรียงลำดับ (Linear search)
เป็นวิธีการค้นหาข้อมูลที่ง่ายและตรงไปตรงมาที่สุด การค้นหาทำได้โดยนำค่าหลักไปเปรียบเทียบกับข้อมูลทั้งหมดทีละตัวตั้งแต่ตัวแรกเรียงตามลำดับจนกว่าจะพบข้อมูลที่ต้องการ
หรือเปรียบเทียบไปจนถึงตัวสุดท้ายและพบว่าไม่มีข้อมูลนี้อยู่
ตัวอย่าง เช่น มีข้อมูลอยู่ 10 จำนวน ดังนี้
18 3 39 70 27 8 1 31 2 50
เมื่อต้องการค้นหาเลขจำนวนเต็ม 2 ให้นำไปเปรียบเทียบกับข้อมูลทีละตัว
เริ่มที่ตัวแรกคือ 18 ถ้าไม่ใช่ข้อมูลที่ต้องการให้ไปเปรียบเทียบกับข้อมูลตัวถัดไป
จนกว่าจะพบข้อมูลที่ต้องการก็หยุดค้น หรือค้นหาจนถึงข้อมูลตัวสุดท้ายแล้วยังไม่พบข้อมูล
ที่ต้องการก็สรุปได้ว่าไม่มีข้อมูลที่ต้องการ ในตัวอย่างนี้การค้นหา 2 ต้องมีการเปรียบเทียบกับค่าต่าง ๆ
ทั้งหมด 9 ครั้ง จึงจะพบข้อมูลที่ต้องการ
การค้นหาแบบเซนทินัล(Sentinel)
เป็นวิธีที่การค้นหาแบบเดียวกับวิธีการค้นหาแบบเชิงเส้นแต่ประสิทธิภาพดีกว่า
ตรงที่เปรียบเทียบน้อยครั้งกว่า วิธีการ คือ
1. เพิ่มขนาดของแถวลำดับ ที่ใช้เก็บข้อมูลอีก 1 ที่
2. นำข้อมูลที่จะใช้ค้นหาข้อมูลใน Array ไปฝากที่ต้นหรือ ท้าย Array
3. ตรวจสอบผลลัพธ์จากการหา โดยตรวจสอบจากตำแหน่งที่พบ ถ้าตำแหน่งที่พบมีค่าเท่ากับ n-1แสดงว่าหาไม่พบนอกนั้นถือว่าพบข้อมูลที่ค้าหา
การค้นหาแบบไบนารี (Binary Search)
เป็นวิธีการค้นหาข้อมูลที่รวดเร็วกว่าการค้นหาแบบเรียงลำดับ แต่วิธีนี้ใช้ได้ในกรณีที่ข้อมูลถูกจัดเก็บแบบเรียงลำดับเรียบร้อยแล้ว โดยอาจจะเรียงลำดับจากน้อยไปมากหรือจากมากไปน้อย การค้นหาข้อมูลด้วยวิธีนี้ ในการเปรียบเทียบแต่ละครั้งสามารถลดจำนวนข้อมูลที่ต้องเปรียบเทียบได้คราวละประมาณครึ่งหนี่งของที่เหลือ
โดยการค้นหาข้อมูลแบบทวิภาคเริ่มต้นด้วยการหาว่าตำแหน่งกึ่งกลางของ ข้อมูลทั้งหมดอยู่ที่ตำแหน่งใด
เนื่องจากข้อมูลทั้งหมดมีการเรียงลำดับค่า ถ้าเรียงจากน้อยไปมาก ข้อมูลที่ตำแหน่งกึ่งกลางจะแบ่งข้อมูลเป็น 2 ส่วน ส่วนแรกเป็นข้อมูลที่มีค่าน้อยกว่าค่าที่ตำแหน่งกึ่งกลาง และส่วนที่ 2 เป็นข้อมูลที่มีค่ามากกว่าค่าที่ตำแหน่ง กึ่งกลาง
สูตรในการค้นหาตำแหน่งตัวเเทน คือ
mid = (low+high)/2mid คือ ตำแหน่งกลาง
low คือ ตำแหน่งต้นแถวลำดับ
high คือ ตำแหน่งท้ายของแถวลำดับ
DTS 10-09-09-2552
สรุป Graph (ต่อ) และ Sorting
การท่องไปในกราฟ
การท่องไปในกราฟ (graph traversal) คือ กระบวนการเข้าไปเยือนโหนดในกราฟ โดยมีหลักในการทำงานคือ แต่ละโหนดจะถูกเยือนเพียงครั้งเดียว สำหรับการท่องไปในทรีเพื่อเยือนแต่ละโหนดนั้นจะมีเส้นทางเดียว แต่ในกราฟระหว่างโหนดอาจจะมีหลายเส้นทาง ดังนั้นเพื่อป้องกันการท่องไปในเส้นทางที่ซ้ำเดิมจึงจำเป็นต้องทำเครื่องหมายมาร์คบิตบริเวณที่ได้เยือนเสร็จเรียบร้อยแล้วเพื่อไม่ให้เข้าไปเยือนอีก สำหรับเทคนิคการท่องไปในกราฟมี 2 แบบดังนี้
1. การท่องแบบกว้าง (breadth first traversal)
วิธีนี้ทำโดยเลือกโหนดที่เป็นจุดเริ่มต้น ต่อมาให้เยือนโหนดอื่นที่ใกล้กันกับโหนดเริ่มต้นทีละระดับจนกระทั่งเยือนหมดทุกโหนดในกราฟ
2. การท่องแบบลึก (depth first traversal)
การทำงานคล้ายกับการท่องทีละระดับของทรี โดยกำหนดเริ่มต้นที่โหนดแรกและเยือนโหนดถัดไปตามแนววิถีนั้นจนกระทั่งนำไปสู่ปลายวิถีนั้น จากนั้น ย้อนกลับ (backtrack) ตามแนววิถีเดิมนั้น จนกระทั่งสามารถดำเนินการต่อเนื่องเข้าสู่แนววิถีอื่น ๆ เพื่อเยือนโหนดอื่น ๆ ต่อไปจนครบทุกโหนด
กราฟมีน้ำหนัก
คือ กราฟที่ทุกเอดจ์มีค่าน้ำหนักกำกับ ค่าน้ำหนักนี้อาจหมายถึงระยะทาง เวลา เป็นต้น ใช้แก้ปัญหา ดังนี้
1.การสร้างต้นไม้ทอดข้ามน้อยที่สุด มีขั้นตอนดังต่อไปนี้
- เรียงเอดจ์ตามน้ำหนัก
- สร้างป่าที่มีแต่ต้นไม้ว่าง
- เลือกเอดจ์ที่มีน้ำหนักน้อยที่สุด และไม่เคยถูกเลือก ถ้าค่าซ้ำกันให้เลือกมา 1 เส้น
- พิจารณาเอดจ์ที่จะเลือกมาประกอบเป็นต้นไม้ทอดข้าม แต่ห้ามเกิดวงรอบ ถ้าเกิดตัดทิ้ง
- ตรวจสอบเอดจ์ที่ต้องอ่านในกราฟ
2.การหาเส้นทางที่สั้นที่สุด
ข้อกำหนดเซต S เก็บโหนดที่ผ่านได้และมีระยะทางจากจุดเริ่มต้นสั้นสุดให้ W แทนโหนดนอกเซตให้ D แทนระยะทางขั้นตอนการทำงาน
- เซต S คือจุดเริ่มต้น
- คำนวณหาระยะทางจากโหนดเริ่มต้นไปยังทุกโหนด โดยยอมให้โหนดในเซต S เป็นทางผ่าน
* ถ้าโหนดในเซต S ที่เป็นทางผ่านมีมากกว่า 1 ให้เลือกระยะทางที่สั้นที่สุดไปใส่ใน D
- เลือกโหนด W ที่ห่างจากจุดเริ่มต้นน้อยที่สุดไปไว้ใน S
การเรียงลำดับ (sorting)
การเรียงลำดับข้อมูลเป็นสิ่งจำเป็นและสำคัญมากในงานที่ต้องการความรวดเร็วในการค้นหาข้อมูล
แม้ว่าในขั้นตอนการเรียงลำดับอาจใช้เวลามากแต่จะมีผลอย่างคุ้มค่ากับการค้นหาข้อมูลในภายหลัง
โดยสามารถค้นหาข้อมูลได้สะดวกและรวดเร็วขึ้นมาก ไม่ว่าการค้นหานั้นจะเป็นการค้นหาด้วยมือหรือด้วยเครื่องคอมพิวเตอร์ก็ตาม
วิธีการเรียงลำดับ
วิธีการเรียงลำดับสามารถแบ่งออกได้ 2 วิธี
1. การเรียงลำดับแบบภายใน (internal sorting)
เป็นการเรียงลำดับที่ข้อมูลทั้งหมดต้องอยู่ในหน่วยความจำหลัก เวลาที่ใช้ในการเรียงลำดับจะคำนึงถึงเวลาที่ใช้ในการเปรียบเทียบและเลื่อนข้อมูลภายในความจำหลัก
2. การเรียงลำดับแบบภายนอก (external sorting)
เป็นการเรียงลำดับข้อมูลที่เก็บอยู่ในหน่วยความจำสำรอง ซึ่งเป็นการเรียงลำดับข้อมูลในแฟ้มข้อมูล (file) นั่นเอง
เวลาที่ใช้ในการเรียงลำดับต้องคำนึงถึงเวลาที่เสียไประหว่างการถ่ายเทข้อมูลจากหน่วยความจำหลักไปยังหน่วยความจำสำรอง และจากหน่วยความจำสำรองไปยังหน่วยความจำหลักด้วย นอกเหนือจากเวลาที่ใช้ในการเรียงลำดับข้อมูลแบบภายใน
การเรียงลำดับแบบเลือก (selection sort)
เป็นวิธีการเรียงลำดับที่จะทำการเลือกข้อมูลมาเก็บในตำแหน่งที่ข้อมูลนั้นควรจะอยู่ทีละตัว โดยทำการค้นหาข้อมูลนั้นในแต่ละรอบแบบเรียงลำดับ ถ้าเป็นการเรียงลำดับจากน้อยไปมาก ในรอบแรกจะทำการค้นหาข้อมูลตัวที่มีค่าน้อยที่สุดมาเก็บไว้ที่ตำแหน่งที่ 1 ในรอบที่สองนำข้อมูลตัวที่มีค่าน้อยรองลงมาไปเก็บไว้ที่ตำแหน่งที่สองทำเช่นนี้ไปเรื่อย ๆ จนกระทั่งครบทุกค่า ในที่สุดจะได้ข้อมูลเรียงลำดับจากน้อยไปมากตามที่ต้องการ
การเรียงลำดับแบบฟอง (Bubble Sort) เป็นวิธีการเรียงลำดับที่มีการเปรียบเทียบข้อมูลในตำแหน่งที่อยู่ติดกัน ถ้าข้อมูลทั้งสองไม่อยู่ในลำดับที่ถูกต้องให้สลับตำแหน่งที่อยู่กันดังนี้ ถ้าเป็นการเรียงลำดับจากน้อยไปมากให้นำข้อมูลตัวที่มี ค่าน้อยกว่าอยู่ในตำแหน่งก่อน และถ้าเป็นการเรียงลำดับจากมากไปน้อยให้นำข้อมูล ตัวที่มีค่ามากกว่าอยู่ในตำแหน่งก่อน ซึ่งวิธีการโดยรวมเป็นการพยายามที่จะลอยหรือดันข้อมูลแต่ละตัวให้ไปอยู่ในตำแหน่งที่ถูกต้องเพื่อเรียงลำดับข้อมูลตามที่ต้องการ
การเรียงลำดับแบบเร็ว (quick sort)
เป็นวิธีการเรียงลำดับที่ใช้เวลาน้อยเหมาะสำหรับข้อมูลที่มีจำนวนมากที่ต้องการความรวดเร็วในการทำงาน
วิธีนี้จะเลือกข้อมูลจากกลุ่มข้อมูลขึ้นมาหนึ่งค่าเป็นค่าหลัก แล้วหาตำแหน่งที่ถูกต้องให้กับค่าหลักนี้ เมื่อได้ตำแหน่งที่ถูกต้องแล้วใช้ค่าหลักนี้เป็นหลักในการแบ่งข้อมูลออกเป็นสองส่วน ถ้าเป็นการเรียงลำดับจากน้อยไปมาก
ส่วนแรกอยู่ในตอนหน้าข้อมูลทั้งหมดจะมีค่าน้อยกว่าค่าหลักที่เป็นตัวแบ่งส่วน และอีกส่วนหนึ่งจะอยู่ในตำแหน่งตอนหลังข้อมูลทั้งหมดจะมีค่ามากกว่าค่าหลัก แล้วนำแต่ละส่วนย่อยไปแบ่งย่อยในลักษณะเดียวกันต่อไป
จนกระทั่งแต่ละส่วนไม่สามารถแบ่งย่อยได้อีกต่อไปจะได้ข้อมูลที่มีการเรียงลำดับตามที่ต้องการ
การเรียงลำดับแบบแทรก (insertion sort)
เป็นวิธีการเรียงลำดับที่ทำการเพิ่มสมาชิกใหม่เข้าไปในเซตที่มีสมาชิกทุกตัวเรียงลำดับอยู่แล้ว และทำให้เซตใหม่ที่ได้นี้มีสมาชิกทุกตัวเรียงลำดับด้วย เป็นวิธีการที่ง่ายไม่ซับซ้อน วิธีการเหมือนการจัดเรียงไพ่ในมือ นั่นคือในขณะเล่นไพ่เรามักเรียงไพ่ในมือตามลำดับตัวเลข และเมื่อหยิบไพ่ใบใหม่เข้ามาเพิ่มจะแทรกลงไประหว่างไพ่ที่เรียงไว้แล้ว โดยจะได้ไพ่ที่เรียงลำดับตัวเลขเช่นกัน
การเรียงลำดับแบบฐาน (radix sort)
เป็นการเรียงลำดับโดยการพิจารณาข้อมูลทีละหลัก เริ่มพิจารณาจากหลักที่มีค่าน้อยที่สุดก่อน นั่นคือถ้าข้อมูลเป็นเลขจำนวนเต็มจะพิจารณาหลักหน่วยก่อน การจัดเรียงจะนำข้อมูลเข้ามาทีละตัว แล้วนำไปเก็บไว้ที่ซึ่งจัดไว้สำหรับค่านั้น เป็นกลุ่ม ๆ ตามลำดับการเข้ามา ในแต่ละรอบเมื่อจัดกลุ่มเรียบร้อยแล้ว ให้รวบรวมข้อมูลจากทุกกลุ่มเข้าด้วยกัน โดยเริ่มเรียงจากกลุ่มที่มีค่าน้อยที่สุดก่อนแล้วเรียงไปเรื่อย ๆ จนหมดทุกกลุ่ม ในรอบต่อไปนำข้อมูลทั้งหมดที่ได้จัดเรียงในหลักหน่วยเรียบร้อยแล้วมาพิจารณาจัดเรียงในหลักสิบต่อไป ทำเช่นนี้ไปเรื่อย ๆ จนกระทั่งครบทุกหลักจะได้ข้อมูลที่เรียงลำดับจากน้อยไปมากตามต้องการ
การท่องไปในกราฟ
การท่องไปในกราฟ (graph traversal) คือ กระบวนการเข้าไปเยือนโหนดในกราฟ โดยมีหลักในการทำงานคือ แต่ละโหนดจะถูกเยือนเพียงครั้งเดียว สำหรับการท่องไปในทรีเพื่อเยือนแต่ละโหนดนั้นจะมีเส้นทางเดียว แต่ในกราฟระหว่างโหนดอาจจะมีหลายเส้นทาง ดังนั้นเพื่อป้องกันการท่องไปในเส้นทางที่ซ้ำเดิมจึงจำเป็นต้องทำเครื่องหมายมาร์คบิตบริเวณที่ได้เยือนเสร็จเรียบร้อยแล้วเพื่อไม่ให้เข้าไปเยือนอีก สำหรับเทคนิคการท่องไปในกราฟมี 2 แบบดังนี้
1. การท่องแบบกว้าง (breadth first traversal)
วิธีนี้ทำโดยเลือกโหนดที่เป็นจุดเริ่มต้น ต่อมาให้เยือนโหนดอื่นที่ใกล้กันกับโหนดเริ่มต้นทีละระดับจนกระทั่งเยือนหมดทุกโหนดในกราฟ
2. การท่องแบบลึก (depth first traversal)
การทำงานคล้ายกับการท่องทีละระดับของทรี โดยกำหนดเริ่มต้นที่โหนดแรกและเยือนโหนดถัดไปตามแนววิถีนั้นจนกระทั่งนำไปสู่ปลายวิถีนั้น จากนั้น ย้อนกลับ (backtrack) ตามแนววิถีเดิมนั้น จนกระทั่งสามารถดำเนินการต่อเนื่องเข้าสู่แนววิถีอื่น ๆ เพื่อเยือนโหนดอื่น ๆ ต่อไปจนครบทุกโหนด
กราฟมีน้ำหนัก
คือ กราฟที่ทุกเอดจ์มีค่าน้ำหนักกำกับ ค่าน้ำหนักนี้อาจหมายถึงระยะทาง เวลา เป็นต้น ใช้แก้ปัญหา ดังนี้
1.การสร้างต้นไม้ทอดข้ามน้อยที่สุด มีขั้นตอนดังต่อไปนี้
- เรียงเอดจ์ตามน้ำหนัก
- สร้างป่าที่มีแต่ต้นไม้ว่าง
- เลือกเอดจ์ที่มีน้ำหนักน้อยที่สุด และไม่เคยถูกเลือก ถ้าค่าซ้ำกันให้เลือกมา 1 เส้น
- พิจารณาเอดจ์ที่จะเลือกมาประกอบเป็นต้นไม้ทอดข้าม แต่ห้ามเกิดวงรอบ ถ้าเกิดตัดทิ้ง
- ตรวจสอบเอดจ์ที่ต้องอ่านในกราฟ
2.การหาเส้นทางที่สั้นที่สุด
ข้อกำหนดเซต S เก็บโหนดที่ผ่านได้และมีระยะทางจากจุดเริ่มต้นสั้นสุดให้ W แทนโหนดนอกเซตให้ D แทนระยะทางขั้นตอนการทำงาน
- เซต S คือจุดเริ่มต้น
- คำนวณหาระยะทางจากโหนดเริ่มต้นไปยังทุกโหนด โดยยอมให้โหนดในเซต S เป็นทางผ่าน
* ถ้าโหนดในเซต S ที่เป็นทางผ่านมีมากกว่า 1 ให้เลือกระยะทางที่สั้นที่สุดไปใส่ใน D
- เลือกโหนด W ที่ห่างจากจุดเริ่มต้นน้อยที่สุดไปไว้ใน S
การเรียงลำดับ (sorting)
การเรียงลำดับข้อมูลเป็นสิ่งจำเป็นและสำคัญมากในงานที่ต้องการความรวดเร็วในการค้นหาข้อมูล
แม้ว่าในขั้นตอนการเรียงลำดับอาจใช้เวลามากแต่จะมีผลอย่างคุ้มค่ากับการค้นหาข้อมูลในภายหลัง
โดยสามารถค้นหาข้อมูลได้สะดวกและรวดเร็วขึ้นมาก ไม่ว่าการค้นหานั้นจะเป็นการค้นหาด้วยมือหรือด้วยเครื่องคอมพิวเตอร์ก็ตาม
วิธีการเรียงลำดับ
วิธีการเรียงลำดับสามารถแบ่งออกได้ 2 วิธี
1. การเรียงลำดับแบบภายใน (internal sorting)
เป็นการเรียงลำดับที่ข้อมูลทั้งหมดต้องอยู่ในหน่วยความจำหลัก เวลาที่ใช้ในการเรียงลำดับจะคำนึงถึงเวลาที่ใช้ในการเปรียบเทียบและเลื่อนข้อมูลภายในความจำหลัก
2. การเรียงลำดับแบบภายนอก (external sorting)
เป็นการเรียงลำดับข้อมูลที่เก็บอยู่ในหน่วยความจำสำรอง ซึ่งเป็นการเรียงลำดับข้อมูลในแฟ้มข้อมูล (file) นั่นเอง
เวลาที่ใช้ในการเรียงลำดับต้องคำนึงถึงเวลาที่เสียไประหว่างการถ่ายเทข้อมูลจากหน่วยความจำหลักไปยังหน่วยความจำสำรอง และจากหน่วยความจำสำรองไปยังหน่วยความจำหลักด้วย นอกเหนือจากเวลาที่ใช้ในการเรียงลำดับข้อมูลแบบภายใน
การเรียงลำดับแบบเลือก (selection sort)
เป็นวิธีการเรียงลำดับที่จะทำการเลือกข้อมูลมาเก็บในตำแหน่งที่ข้อมูลนั้นควรจะอยู่ทีละตัว โดยทำการค้นหาข้อมูลนั้นในแต่ละรอบแบบเรียงลำดับ ถ้าเป็นการเรียงลำดับจากน้อยไปมาก ในรอบแรกจะทำการค้นหาข้อมูลตัวที่มีค่าน้อยที่สุดมาเก็บไว้ที่ตำแหน่งที่ 1 ในรอบที่สองนำข้อมูลตัวที่มีค่าน้อยรองลงมาไปเก็บไว้ที่ตำแหน่งที่สองทำเช่นนี้ไปเรื่อย ๆ จนกระทั่งครบทุกค่า ในที่สุดจะได้ข้อมูลเรียงลำดับจากน้อยไปมากตามที่ต้องการ
การเรียงลำดับแบบฟอง (Bubble Sort) เป็นวิธีการเรียงลำดับที่มีการเปรียบเทียบข้อมูลในตำแหน่งที่อยู่ติดกัน ถ้าข้อมูลทั้งสองไม่อยู่ในลำดับที่ถูกต้องให้สลับตำแหน่งที่อยู่กันดังนี้ ถ้าเป็นการเรียงลำดับจากน้อยไปมากให้นำข้อมูลตัวที่มี ค่าน้อยกว่าอยู่ในตำแหน่งก่อน และถ้าเป็นการเรียงลำดับจากมากไปน้อยให้นำข้อมูล ตัวที่มีค่ามากกว่าอยู่ในตำแหน่งก่อน ซึ่งวิธีการโดยรวมเป็นการพยายามที่จะลอยหรือดันข้อมูลแต่ละตัวให้ไปอยู่ในตำแหน่งที่ถูกต้องเพื่อเรียงลำดับข้อมูลตามที่ต้องการ
การเรียงลำดับแบบเร็ว (quick sort)
เป็นวิธีการเรียงลำดับที่ใช้เวลาน้อยเหมาะสำหรับข้อมูลที่มีจำนวนมากที่ต้องการความรวดเร็วในการทำงาน
วิธีนี้จะเลือกข้อมูลจากกลุ่มข้อมูลขึ้นมาหนึ่งค่าเป็นค่าหลัก แล้วหาตำแหน่งที่ถูกต้องให้กับค่าหลักนี้ เมื่อได้ตำแหน่งที่ถูกต้องแล้วใช้ค่าหลักนี้เป็นหลักในการแบ่งข้อมูลออกเป็นสองส่วน ถ้าเป็นการเรียงลำดับจากน้อยไปมาก
ส่วนแรกอยู่ในตอนหน้าข้อมูลทั้งหมดจะมีค่าน้อยกว่าค่าหลักที่เป็นตัวแบ่งส่วน และอีกส่วนหนึ่งจะอยู่ในตำแหน่งตอนหลังข้อมูลทั้งหมดจะมีค่ามากกว่าค่าหลัก แล้วนำแต่ละส่วนย่อยไปแบ่งย่อยในลักษณะเดียวกันต่อไป
จนกระทั่งแต่ละส่วนไม่สามารถแบ่งย่อยได้อีกต่อไปจะได้ข้อมูลที่มีการเรียงลำดับตามที่ต้องการ
การเรียงลำดับแบบแทรก (insertion sort)
เป็นวิธีการเรียงลำดับที่ทำการเพิ่มสมาชิกใหม่เข้าไปในเซตที่มีสมาชิกทุกตัวเรียงลำดับอยู่แล้ว และทำให้เซตใหม่ที่ได้นี้มีสมาชิกทุกตัวเรียงลำดับด้วย เป็นวิธีการที่ง่ายไม่ซับซ้อน วิธีการเหมือนการจัดเรียงไพ่ในมือ นั่นคือในขณะเล่นไพ่เรามักเรียงไพ่ในมือตามลำดับตัวเลข และเมื่อหยิบไพ่ใบใหม่เข้ามาเพิ่มจะแทรกลงไประหว่างไพ่ที่เรียงไว้แล้ว โดยจะได้ไพ่ที่เรียงลำดับตัวเลขเช่นกัน
การเรียงลำดับแบบฐาน (radix sort)
เป็นการเรียงลำดับโดยการพิจารณาข้อมูลทีละหลัก เริ่มพิจารณาจากหลักที่มีค่าน้อยที่สุดก่อน นั่นคือถ้าข้อมูลเป็นเลขจำนวนเต็มจะพิจารณาหลักหน่วยก่อน การจัดเรียงจะนำข้อมูลเข้ามาทีละตัว แล้วนำไปเก็บไว้ที่ซึ่งจัดไว้สำหรับค่านั้น เป็นกลุ่ม ๆ ตามลำดับการเข้ามา ในแต่ละรอบเมื่อจัดกลุ่มเรียบร้อยแล้ว ให้รวบรวมข้อมูลจากทุกกลุ่มเข้าด้วยกัน โดยเริ่มเรียงจากกลุ่มที่มีค่าน้อยที่สุดก่อนแล้วเรียงไปเรื่อย ๆ จนหมดทุกกลุ่ม ในรอบต่อไปนำข้อมูลทั้งหมดที่ได้จัดเรียงในหลักหน่วยเรียบร้อยแล้วมาพิจารณาจัดเรียงในหลักสิบต่อไป ทำเช่นนี้ไปเรื่อย ๆ จนกระทั่งครบทุกหลักจะได้ข้อมูลที่เรียงลำดับจากน้อยไปมากตามต้องการ
วันเสาร์ที่ 12 กันยายน พ.ศ. 2552
DTS 09-02-09-2552
สรุป TREE (ต่อ) และ Graph
เอ็กซ์เพรสชันทรี
เป็นการนำเอาโครงสร้างทรีไปใช้เก็บนิพจน์ทางคณิตศาสตร์โดยเป็นไบนารีทรี
ซึ่งแต่ละโหนดเก็บตัวดำเนินการ(Operator) และตัวถูกดำเนินการ(Operand)
ของนิพจน์คณิตศาสตร์นั้นๆ ไว้ หรืออาจจะเก็บค่านิพจนทางตรรกะ
นิพจน์เหล่านี้เมื่อแทนในทรีต้องคำนึงลำดับขั้นตอนในการคำนวณตามความสำคัญของเครื่องหมายด้วย
1.ฟังก์ชัน
2.วงเล็บ
3.ยกกำลัง
4.เครื่องหมายหน้าเลขจำนวน
5.คูณหรือหาร
6.บวกหรือลบ
7.ถ้ามีเครื่องหมายที่ระดับเดียวกันให้ทำจากซ้ายไปขวา
ไบนารีเซิร์ชทรี (Binary Search Tree)
เป็นไบนารีทรีที่มีคุณสมบัติที่ว่าทุก ๆ โหนดในทรี
ค่าของโหนดรากมีค่ามากกว่าค่าของทุกโหนดในทรีย่อยทางซ้าย
และมีค่าน้อยกว่าหรือเท่ากับค่าของทุกโหนดในทรีย่อยทางขวา
และในแต่ละทรีย่อยก็มีคุณสมบัติเช่นเดียวกัน คือ
ค่าข้อมูลในทรีย่อยทางซ้าย < ค่าข้อมูลที่โหนดราก < ค่าข้อมูลในทรีย่อยทางขวา ปฏิบัติการในไบนารีเซิร์ชทรี
เพิ่มโหนดเข้าหรือดึงโหนดออกจากไบนารีเซิร์ชทรี ค่อนข้างยุ่งยาก
เนื่องจากหลังปฏิบัติการเสร็จเรียบร้อยแล้ว ต้องคำนึงถึงความเป็นไบนารีเซิร์ชทรีทรีนั้นด้วย
ซึ่งมีปฏิบัติการดังต่อไปนี้
1. การเพิ่มโหนดในไบนารีเซิร์ชทรี
2. การดึงโหนดในไบนารีเซิร์ชทรี ขั้นตอนวิธีดึงโหนดออกอาจแยกพิจารณาได้ 3 กรณีดังต่อไปนี้
ก. กรณีโหนดที่จะดึงออกเป็นโหนดใบ
ข. กรณีโหนดที่ดึงออกมีเฉพาะทรีย่อยทางซ้ายหรือทรีย่อยทางขวาเพียงด้านใดด้านหนึ่ง
ค. กรณีโหนดที่ดึงออกมีทั้งทรีย่อยทาง
Graph
กราฟ เป็นโครสร้างข้อมูบแบบไม่ใช่เชิงเส้น ที่ประกอบ ด้วยกลุ่มของสิ่งสองสิ่งคือ
(1) โหนด (Nodes) หรือ เวอร์เทกซ์(Vertexes)
(2) เส้นเชื่อมระหว่างโหนด เรียก เอ็จ (Edges)
โดยทั่ว ๆ ไปการเขียนกราฟเพื่อแสดงให้เห็นความสัมพันธ์ของสิ่งที่เราสนใจแทนโหนดด้วย
จุด (pointes) หรือวงกลม (circles) ที่มีชื่อหรือข้อมูลกำกับ
เพื่อบอกความแตกต่างของแต่ละโหนด และเอ็จแทนด้วยเส้นหรือเส้นโค้ง
เชื่อมต่อระหว่างโหนดสองโหนด ถ้าเป็นกราฟแบบมีทิศทางเส้นหรือเส้นโค้ง
ต้องมีหัวลูกศรกำกับทิศทางของความสัมพันธ์ด้วย
การแทนกราฟในหน่วยความจำ
ในการปฏิบัติการกับโครงสร้างกราฟ สิ่งที่เราต้องการจัดเก็บจากกราฟโดยทั่วไปก็คือ เอ็จ
ซึ่งเป็นเส้นเชื่อมระหว่างโหนดสองโหนด มีวิธีการจัดเก็บหลายวิธี
วิธีที่ง่ายและตรงไปตรงมาที่สุดคือ การเก็บเอ็จในแถวลำดับ 2 มิติ
กราฟที่มีการเปลี่ยนแปลงตลอดเวลา อาจจะใช้วิธีแอดจาเซนซีลิสต์ (adjacency list)
ซึ่งเป็นวิธีที่คล้ายวิธีจัดเก็บกราฟด้วยการเก็บโหนดและพอยน์เตอร์ที่กล่าวมาแล้วข้างต้น
แต่ต่างกันตรงที่แทนที่จะเก็บโหนดที่มีความสัมพันธ์ด้วยไว้ในแถวลำดับ 1 มิติ
จะใช้ลิงค์ลิสต์แทนเพื่อความสะดวกในการเปลี่ยนแปลงแก้ไข
การท่องไปในกราฟ
การท่องไปในกราฟ (graph traversal) คือ กระบวนการเข้าไปเยือนโหนดในกราฟ
โดยมีหลักในการทำงานคือ แต่ละโหนดจะถูกเยือนเพียงครั้งเดียว
สำหรับการท่องไปในทรีเพื่อเยือนแต่ละโหนดนั้นจะมีเส้นทางเดียว
แต่ในกราฟระหว่างโหนดอาจจะมีหลายเส้นทาง
ดังนั้นเพื่อป้องกันการท่องไปในเส้นทางที่ซ้ำเดิมจึงจำเป็นต้องทำเครื่องหมายมาร์คบิตบริเวณที่ได้เยือนเสร็จเรียบร้อยแล้วเพื่อไม่ให้เข้าไปเยือนอีก สำหรับเทคนิคการท่องไปในกราฟมี 2 แบบดังนี้
1. การท่องแบบกว้าง (breadth first traversal)
วิธีนี้ทำโดยเลือกโหนดที่เป็นจุดเริ่มต้น ต่อมาให้เยือนโหนดอื่นที่ใกล้กันกับโหนดเริ่มต้นทีละระดับจนกระทั่งเยือนหมดทุกโหนดในกราฟ
2. การท่องแบบลึก (depth first traversal)
การทำงานคล้ายกับการท่องทีละระดับของทรี โดยกำหนดเริ่มต้นที่โหนดแรกและเยือนโหนดถัดไปตามแนววิถีนั้นจนกระทั่งนำไปสู่ปลายวิถีนั้น จากนั้น ย้อนกลับ (backtrack) ตามแนววิถีเดิมนั้น จนกระทั่งสามารถดำเนินการต่อเนื่องเข้าสู่แนววิถีอื่น ๆ เพื่อเยือนโหนดอื่น ๆ ต่อไปจนครบทุกโหนด
เอ็กซ์เพรสชันทรี
เป็นการนำเอาโครงสร้างทรีไปใช้เก็บนิพจน์ทางคณิตศาสตร์โดยเป็นไบนารีทรี
ซึ่งแต่ละโหนดเก็บตัวดำเนินการ(Operator) และตัวถูกดำเนินการ(Operand)
ของนิพจน์คณิตศาสตร์นั้นๆ ไว้ หรืออาจจะเก็บค่านิพจนทางตรรกะ
นิพจน์เหล่านี้เมื่อแทนในทรีต้องคำนึงลำดับขั้นตอนในการคำนวณตามความสำคัญของเครื่องหมายด้วย
1.ฟังก์ชัน
2.วงเล็บ
3.ยกกำลัง
4.เครื่องหมายหน้าเลขจำนวน
5.คูณหรือหาร
6.บวกหรือลบ
7.ถ้ามีเครื่องหมายที่ระดับเดียวกันให้ทำจากซ้ายไปขวา
ไบนารีเซิร์ชทรี (Binary Search Tree)
เป็นไบนารีทรีที่มีคุณสมบัติที่ว่าทุก ๆ โหนดในทรี
ค่าของโหนดรากมีค่ามากกว่าค่าของทุกโหนดในทรีย่อยทางซ้าย
และมีค่าน้อยกว่าหรือเท่ากับค่าของทุกโหนดในทรีย่อยทางขวา
และในแต่ละทรีย่อยก็มีคุณสมบัติเช่นเดียวกัน คือ
ค่าข้อมูลในทรีย่อยทางซ้าย < ค่าข้อมูลที่โหนดราก < ค่าข้อมูลในทรีย่อยทางขวา ปฏิบัติการในไบนารีเซิร์ชทรี
เพิ่มโหนดเข้าหรือดึงโหนดออกจากไบนารีเซิร์ชทรี ค่อนข้างยุ่งยาก
เนื่องจากหลังปฏิบัติการเสร็จเรียบร้อยแล้ว ต้องคำนึงถึงความเป็นไบนารีเซิร์ชทรีทรีนั้นด้วย
ซึ่งมีปฏิบัติการดังต่อไปนี้
1. การเพิ่มโหนดในไบนารีเซิร์ชทรี
2. การดึงโหนดในไบนารีเซิร์ชทรี ขั้นตอนวิธีดึงโหนดออกอาจแยกพิจารณาได้ 3 กรณีดังต่อไปนี้
ก. กรณีโหนดที่จะดึงออกเป็นโหนดใบ
ข. กรณีโหนดที่ดึงออกมีเฉพาะทรีย่อยทางซ้ายหรือทรีย่อยทางขวาเพียงด้านใดด้านหนึ่ง
ค. กรณีโหนดที่ดึงออกมีทั้งทรีย่อยทาง
Graph
กราฟ เป็นโครสร้างข้อมูบแบบไม่ใช่เชิงเส้น ที่ประกอบ ด้วยกลุ่มของสิ่งสองสิ่งคือ
(1) โหนด (Nodes) หรือ เวอร์เทกซ์(Vertexes)
(2) เส้นเชื่อมระหว่างโหนด เรียก เอ็จ (Edges)
โดยทั่ว ๆ ไปการเขียนกราฟเพื่อแสดงให้เห็นความสัมพันธ์ของสิ่งที่เราสนใจแทนโหนดด้วย
จุด (pointes) หรือวงกลม (circles) ที่มีชื่อหรือข้อมูลกำกับ
เพื่อบอกความแตกต่างของแต่ละโหนด และเอ็จแทนด้วยเส้นหรือเส้นโค้ง
เชื่อมต่อระหว่างโหนดสองโหนด ถ้าเป็นกราฟแบบมีทิศทางเส้นหรือเส้นโค้ง
ต้องมีหัวลูกศรกำกับทิศทางของความสัมพันธ์ด้วย
การแทนกราฟในหน่วยความจำ
ในการปฏิบัติการกับโครงสร้างกราฟ สิ่งที่เราต้องการจัดเก็บจากกราฟโดยทั่วไปก็คือ เอ็จ
ซึ่งเป็นเส้นเชื่อมระหว่างโหนดสองโหนด มีวิธีการจัดเก็บหลายวิธี
วิธีที่ง่ายและตรงไปตรงมาที่สุดคือ การเก็บเอ็จในแถวลำดับ 2 มิติ
กราฟที่มีการเปลี่ยนแปลงตลอดเวลา อาจจะใช้วิธีแอดจาเซนซีลิสต์ (adjacency list)
ซึ่งเป็นวิธีที่คล้ายวิธีจัดเก็บกราฟด้วยการเก็บโหนดและพอยน์เตอร์ที่กล่าวมาแล้วข้างต้น
แต่ต่างกันตรงที่แทนที่จะเก็บโหนดที่มีความสัมพันธ์ด้วยไว้ในแถวลำดับ 1 มิติ
จะใช้ลิงค์ลิสต์แทนเพื่อความสะดวกในการเปลี่ยนแปลงแก้ไข
การท่องไปในกราฟ
การท่องไปในกราฟ (graph traversal) คือ กระบวนการเข้าไปเยือนโหนดในกราฟ
โดยมีหลักในการทำงานคือ แต่ละโหนดจะถูกเยือนเพียงครั้งเดียว
สำหรับการท่องไปในทรีเพื่อเยือนแต่ละโหนดนั้นจะมีเส้นทางเดียว
แต่ในกราฟระหว่างโหนดอาจจะมีหลายเส้นทาง
ดังนั้นเพื่อป้องกันการท่องไปในเส้นทางที่ซ้ำเดิมจึงจำเป็นต้องทำเครื่องหมายมาร์คบิตบริเวณที่ได้เยือนเสร็จเรียบร้อยแล้วเพื่อไม่ให้เข้าไปเยือนอีก สำหรับเทคนิคการท่องไปในกราฟมี 2 แบบดังนี้
1. การท่องแบบกว้าง (breadth first traversal)
วิธีนี้ทำโดยเลือกโหนดที่เป็นจุดเริ่มต้น ต่อมาให้เยือนโหนดอื่นที่ใกล้กันกับโหนดเริ่มต้นทีละระดับจนกระทั่งเยือนหมดทุกโหนดในกราฟ
2. การท่องแบบลึก (depth first traversal)
การทำงานคล้ายกับการท่องทีละระดับของทรี โดยกำหนดเริ่มต้นที่โหนดแรกและเยือนโหนดถัดไปตามแนววิถีนั้นจนกระทั่งนำไปสู่ปลายวิถีนั้น จากนั้น ย้อนกลับ (backtrack) ตามแนววิถีเดิมนั้น จนกระทั่งสามารถดำเนินการต่อเนื่องเข้าสู่แนววิถีอื่น ๆ เพื่อเยือนโหนดอื่น ๆ ต่อไปจนครบทุกโหนด
วันอาทิตย์ที่ 30 สิงหาคม พ.ศ. 2552
DTS 08-26-08-2552
สรุป Tree
ทรี หรือโครงสร้างข้อมูลแบบต้นไม้ ประกอบด้วยโหนด (node) ซึ่งเป็นส่วนที่เก็บข้อมูล ในทรีหนึ่งทรีจะประกอบไปด้วยรูทโหนด (root node) เพียงหนึ่งโหนด แล้วรูทโหนดสามารถแตกโหนดออกเป็นโหนดย่อยๆ ได้อีกหลายโหนดเรียกว่าโหนดลูก (Child node) เมื่อมีโหนดลูกแล้ว โหนดลูกก็ยังสามารถแสดงเป็นโหนดพ่อแม่ (Parent Node) โดยการแตกโหนดออกเป็นโหนดย่อยๆได้อีก
โดยทั่วไปแต่ละโหนดในทรีจะมีความสัมพันธ์กับโหนดในระดับที่ต่ำลงมาหนึ่งระดับได้หลาย ๆ โหนด
หรืออาจกล่าวได้ว่าแต่ละโหนดของทรีเป็น
โหนดแม่ (parent or mother node) ของโหนดลูก (child or son node)
ซึ่งเป็นโหนดที่อยู่ในระดับต่ำลงมาหนึ่งระดับโดยสามารถมีโหนดลูกได้หลาย ๆ โหนด
และโหนดต่าง ๆ ที่มีโหนดแม่เป็นโหนดเดียวกันเรียกว่า โหนดพี่น้อง (siblings)
ทุก ๆ โหนดต้องมีโหนดแม่เสมอยกเว้นโหนดในระดับสูงสุดไม่มีโหนดแม่เรียกโหนดนี้ว่า
โหนดราก (root node) โหนดที่ไม่มีโหนดลูกเลยเรียกว่า โหนดใบ (leave node)
และเส้นเชื่อมแสดงความสัมพันธ์ระหว่างโหนดสองโหนดเรียกว่า กิ่ง (branch)
Binary Tree
Binary Tree มีลักษณะเหมือนกับ Tree ปกติแต่มีคุณสมบัติพิเศษ คือ “แต่ละโหนดจะมีโหนดลูกได้ไม่เกิน 2 โหนด”
หรือพูดอีกนัยหนึ่งก็คือ แต่ละโหนดใน binary tree จะมีดีกรีได้ไม่เกิน 2
ตัวอย่าง binary tree
ทรี หรือโครงสร้างข้อมูลแบบต้นไม้ ประกอบด้วยโหนด (node) ซึ่งเป็นส่วนที่เก็บข้อมูล ในทรีหนึ่งทรีจะประกอบไปด้วยรูทโหนด (root node) เพียงหนึ่งโหนด แล้วรูทโหนดสามารถแตกโหนดออกเป็นโหนดย่อยๆ ได้อีกหลายโหนดเรียกว่าโหนดลูก (Child node) เมื่อมีโหนดลูกแล้ว โหนดลูกก็ยังสามารถแสดงเป็นโหนดพ่อแม่ (Parent Node) โดยการแตกโหนดออกเป็นโหนดย่อยๆได้อีก
โดยทั่วไปแต่ละโหนดในทรีจะมีความสัมพันธ์กับโหนดในระดับที่ต่ำลงมาหนึ่งระดับได้หลาย ๆ โหนด
หรืออาจกล่าวได้ว่าแต่ละโหนดของทรีเป็น
โหนดแม่ (parent or mother node) ของโหนดลูก (child or son node)
ซึ่งเป็นโหนดที่อยู่ในระดับต่ำลงมาหนึ่งระดับโดยสามารถมีโหนดลูกได้หลาย ๆ โหนด
และโหนดต่าง ๆ ที่มีโหนดแม่เป็นโหนดเดียวกันเรียกว่า โหนดพี่น้อง (siblings)
ทุก ๆ โหนดต้องมีโหนดแม่เสมอยกเว้นโหนดในระดับสูงสุดไม่มีโหนดแม่เรียกโหนดนี้ว่า
โหนดราก (root node) โหนดที่ไม่มีโหนดลูกเลยเรียกว่า โหนดใบ (leave node)
และเส้นเชื่อมแสดงความสัมพันธ์ระหว่างโหนดสองโหนดเรียกว่า กิ่ง (branch)
Binary Tree
Binary Tree มีลักษณะเหมือนกับ Tree ปกติแต่มีคุณสมบัติพิเศษ คือ “แต่ละโหนดจะมีโหนดลูกได้ไม่เกิน 2 โหนด”
หรือพูดอีกนัยหนึ่งก็คือ แต่ละโหนดใน binary tree จะมีดีกรีได้ไม่เกิน 2
ตัวอย่าง binary tree

นิยามของทรี
นิยามทรีมีนิยามในรูปแบบต่าง ๆ กัน เช่น นิยามทรีในรูปแบบนิยามของกราฟ นิยามทรีในรูปแบบรีเคอร์ซีฟ และมีนิยามต่าง ๆ ที่เกี่ยวข้องกับทรีดังนี้
นิยามทรีด้วยนิยามของกราฟ เนื่องจากรูปแบบของทรี เป็นรูปแบบเฉพาะอย่างหนึ่งของกราฟ (graph)
ทรี คือกราฟที่ต่อเนื่องกันโดยไม่มีวงจรปิด (loop) ในโครงสร้าง นั่นคือทรีจะต้องมีคุณสมบัติดังนี้
(1) โหนดสองโหนดใด ๆ ในทรีต้องมีทางติดต่อกันทางเดียวเท่านั้น
(2) ทรีที่มี N โหนด ต้องมีกิ่งทั้งหมด N-1 เส้น
นิยามทรีด้วยรูปแบบรีเคอร์ซีฟ
การกำหนดนิยามของ ทรีอาจกำหนดได้อีกวิธีหนึ่งเป็นการนิยามแบบรีเคอร์ซีฟ คือ ทรีประกอบด้วยสมาชิกที่เรียกว่า โหนด โดยที่
(1) ว่าง ไม่มีโหนดเลยเรียกว่า นัลทรี (null tree)
(2) มีโหนดหนึ่งเป็นโหนดราก ส่วนที่เหลือแบ่งเป็นทรีย่อย (sub tree) T1, T2, T3, ... , Tk (โดยที่ k³0) และทรีย่อยต้องมีคุณสมบัติเป็นทรี
นิยามที่เกี่ยวข้องกับทรี มีนิยามต่าง ๆ ที่เกี่ยวข้องกับ ทรีมากมายดังต่อไปนี้
(1) ฟอร์เรสต์ (forest) หมายถึงกลุ่มของทรีที่เกิดจากการเอาโหนดรากของทรีออก หรือเซตของทรีที่แยกจากกัน (disjoint trees)
(2) ทรีที่มีแบบแผน (ordered tree) หมายถึงทรีที่โหนดต่าง ๆ ในทรีนั้นมีความสัมพันธ์ที่แน่นอน เช่น ก่อน ไปทางขวา ไปทางซ้าย เป็นต้น
(3) ทรีคล้าย (similar tree) คือ ทรีที่มีโครงสร้างเหมือนกัน หรือทรีที่มีรูปร่างของทรีเหมือนกันนั่นเองโดยไม่คำนึงถึงข้อมูลที่อยู่ในแต่ละโหนด
(4) ทรีเหมือน (equivalent tree) หมายถึงทรีที่เหมือนกันโดยสมบูรณ์ (equivalence) โดยต้องเป็นทรีที่คล้ายกันและแต่ละโหนดในตำแหน่งเดียวกันมีข้อมูลเหมือนกัน
(5) กำลัง (degree) หมายถึง จำนวนทรีย่อยของโหนดนั้น ๆ
(6) ระดับของโหนด (level of node) คือ ระยะทางในแนวดิ่งของโหนดนั้น ๆ ที่อยู่ห่างจากโหนดราก เมื่อกำหนดให้โหนดรากของทรีนั้นอยู่ที่ระดับ 1 และกิ่งแต่ละกิ่งมีความเท่ากันหมดคือยาวเท่ากับ 1 หน่วย ซึ่งระดับของโหนดจะเท่ากับจำนวนกิ่งที่น้อยที่สุดจากโหนดรากไปยังโหนดใด ๆ บวกด้วย 1
การแทนที่ทรีในความจำหลัก
การแทนที่โครงสร้างข้อมูลแบบทรีในความจำหลักสามารถแทนที่แบบสแตติก หรือแบบไดนามิกก็ได้ โดยมีพอยน์เตอร์เชื่อมโยงจากโหนดแม่ไปยังโหนดลูก แต่ละโหนดต้องมีลิงค์ฟิลด์หลายลิงค์ฟิลด์เพื่อเก็บที่อยู่ของโหนดลูกต่าง ๆ นั่นคือ จำนวนลิงค์ฟิลด์ของแต่ละโหนดขึ้นอยู่กับจำนวนของโหนดลูก การแทนที่ทรีซึ่งแต่ละโหนดมีจำนวนลิงค์ฟิลด์ไม่เท่ากัน ทำให้ยากต่อการปฏิบัติการเป็นอย่างยิ่ง มีวิธีการแทนที่ทรีในหน่วยความจำหลายวิธี วิธีที่ง่ายที่สุดคือทำให้แต่ละโหนดมีจำนวนลิงค์ฟิลด์เท่ากัน โดยอาจจะใช้วิธีการต่อไปนี้
แต่ละโหนดเก็บพอยน์เตอร์ชี้ไปยังโหนดลูกทุกโหนด
การแทนที่ทรีในหน่วยความจำวิธีนี้ จะให้จำนวนฟิลด์ในแต่ละโหนดเท่ากัน โดยกำหนดจำนวนลิงค์ฟิลด์ทุกโหนดมีขนาดเท่ากับจำนวนโหนดลูกของโหนดที่มีลูกมากที่สุด โหนดใดไม่มีโหนดลูกก็ให้ค่าพอยน์เตอร์ในลิงค์ฟิลด์นั้น ๆ มีค่าเป็นนัล โดยให้ลิงค์ฟิลด์แรกเก็บค่าพอยน์เตอร์ชี้ไปยังโหนดลูกลำดับที่หนึ่ง ลิงค์ฟิลด์ที่สองเก็บค่าพอยน์เตอร์ชี้ไปยังโหนดลูกในลำดับที่สอง และลิงค์ฟิลด์อื่นเก็บค่าพอยน์เตอร์ของโหนดลูกในลำดับถัดไปเรื่อย ๆ
การแทนทรีด้วยโหนดขนาดเท่ากันค่อนข้างใช้เนื้อที่จำนวนมาก เนื่องจากแต่ละโหนดมีจำนวนโหนดลูกไม่เท่ากันหรือบางโหนดไม่มีโหนดลูกเลย ถ้าเป็นทรีที่แต่ละโหนดมีจำนวนโหนดลูกที่แตกต่างกันมาก เช่น ทรีที่มีบางโหนดมีจำนวนโหนดลูกสูงสุดเป็น 15 โหนด ในขณะที่โหนดอื่น ๆ ส่วนใหญ่มีจำนวนโหนดลูกแค่ 1 ถึง 2 โหนดเท่านั้น เราจะต้องกำหนดให้แต่ละโหนดมีลิงค์ฟิลด์ทั้งหมดเป็น 15 ลิงค์ฟิลด์ ทั้ง ๆ ที่ลิงค์ฟิลด์ส่วนใหญ่มีค่าเป็นนัล ทำให้ลิงค์ฟิลด์บางลิงค์ฟิลด์ไม่ได้ใช้ประโยชน์เลย เป็นการสิ้นเปลืองเนื้อที่ในหน่วยความจำโดยเปล่าประโยชน์
แทนทรีด้วยไบนารีทรี
วิธีแก้ปัญหาเพื่อลดการสิ้นเปลืองเนื้อที่ในหน่วยความจำก็คือกำหนดลิงค์ฟิลด์ให้มีจำนวนน้อยที่สุดเท่าที่จำเป็นเท่านั้น ถ้ากำหนดให้แต่ละโหนดมีจำนวนลิงค์ฟิลด์สองลิงค์ฟิลด์ โดยให้ลิงค์ฟิลด์แรกเก็บที่อยู่ของโหนดลูกคนโต และลิงค์ฟิลด์ที่สองเก็บที่อยู่ของโหนดพี่น้องที่เป็นโหนดถัดไป โหนดใดไม่มีโหนดลูกหรือไม่มีโหนดพี่น้องให้ค่าพอยน์เตอร์ในลิงค์ฟิลด์มีค่าเป็นนัล
การแปลงทรีทั่วไปให้เป็นไบนารีทรี
ขั้นตอนการแปลงทรีทั่ว ๆ ไปให้เป็นไบนารีทรี ที่ความสัมพันธ์ของการจัดเก็บเหมือนกับที่กล่าวมาแล้วข้างต้นในทรีรูปที่ 7.14 นั่นคือแต่ละโหนดมี 2 ลิงค์ฟิลด์ ค่าพอยน์เตอร์ในลิงค์ฟิลด์แรกเก็บที่อยู่ของโหนดลูกคนโต และค่าพอยน์เตอร์ในลิงค์ฟิลด์ที่สองเก็บที่อยู่ของโหนดพี่น้องคนถัดไป มีลำดับขั้นตอนการแปลงดังต่อไปนี้
(1) ให้โหนดแม่ชี้ไปยังโหนดลูกคนโต แล้วลบความสัมพันธ์ระหว่างโหนดแม่และโหนดลูกอื่น ๆ
(2) ให้เชื่อมความสัมพันธ์ระหว่างโหนดพี่น้อง
(3) จับให้ทรีย่อยทางขวาเอียงลงมา 45 องศา
การท่องไปในไบนารีทรี
ปฏิบัติการที่สำคัญในไบนารีทรี คือ การท่องไปในไบนารีทรี (traversing binary tree) เพื่อเข้าไปเยือนทุก ๆ โหนดในทรี ซึ่งวิธีการท่องเข้าไปต้องเป็นไปอย่างมีระบบแบบแผน สามารถเยือนโหนดทุก ๆ โหนด ๆ ละหนึ่งครั้ง วิธีการท่องไปนั้นมีด้วยกันหลายแบบแล้วแต่ว่าต้องการลำดับขั้นตอนการเยือนอย่างไรในการเยือนแต่ละครั้ง โหนดที่ถูกเยือนอาจเป็นโหนดแม่ (แทนด้วย N) ทรีย่อยทางซ้าย (แทนด้วย L) หรือทรีย่อยทางขวา (แทนด้วย R) มีวิธีการท่องเข้าไปในทรี 6 วิธี คือ
การท่องไปแบบพรีออร์เดอร์ (preorder traversal)
เป็นการเดินเข้าไปเยือนโหนดต่าง ๆ ในทรีด้วยวิธี NLR มีขั้นตอนการเดินดังต่อไปนี้
(1) เยือนโหนดราก
(2) ท่องไปในทรีย่อยทางซ้ายแบบพรีออร์เดอร์
(3) ท่องไปในทรีย่อยทางขวาแบบพรีออร์เดอร์
การท่องไปแบบอินออร์เดอร์ (inorder traversal)
เป็นการเดินเข้าไปเยือนโหนดต่าง ๆ ในทรีด้วยวิธี LNR ซึ่งมีขั้นตอนการเดินดังต่อไปนี้
(1) ท่องไปในทรีย่อยทางซ้ายแบบอินออร์เดอร์
(2) เยือนโหนดราก
(3) ท่องไปในทรีย่อยทางขวาแบบอินออร์เดอร์
การท่องไปแบบโพสออร์เดอร์ (postorder traversal)
เป็นการเดินเข้าไปเยือนโหนดต่าง ๆ ในทรี ด้วยวิธี LRN ซึ่งมีขั้นตอนการเดินดังต่อไปนี้
(1) ท่องไปในทรีย่อยทางซ้ายแบบโพสออร์เดอร์
(2) ท่องไปในทรีย่อยทางขวาแบบโพสออร์เดอร์
(3) เยือนโหนดราก
DTS 07-05-08-2552
สรุป Queue
คิวเป็นโครงสร้างข้อมูลแบบลำดับ (Sequential) ลักษณะของคิวเราสามารถพบได้ในชีวิตประจำวัน เช่น การเข้าแถวตามคิวเพื่อรอรับบริการต่างๆ ลำดับการสั่งพิมพ์งาน เป็นต้น ซึ่งจะเห็นได้ว่าลักษณะของการทำงานจะเป็นแบบใครมาเข้าคิวก่อน จะได้รับบริการก่อน เรียกได้ว่าเป็นลักษณะการทำงานแบบ FIFO (First In , First Out)
การทำงานของคิว (queue)
1.) Create Queue
เป็นการจัดสรรหน่วยความจำให้กับ Head Node และให้ค่า pointer ทั้ง 2 ตัวมีค่าป็น null และจำนวนสมาชิกเป็นศูนย์
2.) Enqueue
เป็นการเพิ่มข้อมูลเข้าไปในคิว ซึ่ง pointer rear จะเปลี่ยน
3.) Dequeue
เป็นการนำข้อมูลออกจากคิว ซึ่ง pointer front จะเปลี่ยน
4.) Queue Front
เป็นการนำข้อมูลที่อยู่ตอนต้นของคิวมาแสดง
5.) Queue Rear
เป็นการนำข้อมูลที่อยู่ส่วนท้ายของคิวมาแสดง
6.) Empty Queue
เป็นการตรวจสอบว่าคิวว่างหรือไม่
7.) Full Queue
เป็นการตรวจสอบว่าคิวเต็มหรือไม่
8.) Queue Count
เป็นการนับจำนวนสมาชิกที่อยู่ในคิว
9.) Destroy Queue
เป็นการลบข้อมูลทั้งหมดที่อยู่ในคิว วิธีการคือ ต้องทำการ Dequeue ทีละตัว แล้วจึงจะ Destroy
คิวเป็นโครงสร้างข้อมูลแบบลำดับ (Sequential) ลักษณะของคิวเราสามารถพบได้ในชีวิตประจำวัน เช่น การเข้าแถวตามคิวเพื่อรอรับบริการต่างๆ ลำดับการสั่งพิมพ์งาน เป็นต้น ซึ่งจะเห็นได้ว่าลักษณะของการทำงานจะเป็นแบบใครมาเข้าคิวก่อน จะได้รับบริการก่อน เรียกได้ว่าเป็นลักษณะการทำงานแบบ FIFO (First In , First Out)
การทำงานของคิว (queue)
การใส่สมาชิกตัวใหม่ลงในคิวเรียกว่า Enqueue
และการนำข้อมูลออกจาก คิวเรียกว่า Dequeue
ซึ่งมีรูปแบบคือ enqueue () การแทนที่ข้อมูลของคิว (queue)
1.การแทนที่ข้อมูลแบบลิงค์ลิสตจะประกอบไปด้วย2ส่วนคือ
1.1Head Node จะประกอบไปด้วย3ส่วนคือ พอยเตอร์จำนวน2ตัวคือ Front และ Rear
กับจำนวนสมาชิกในคิว
1.2Data Node จะประกอบไปด้วยข้อมูล Data และพอยเตอร์ที่่ชี้ไปยัง ข้อมูลตัวถัดไป
2.การแทนที่ข้อมูลแบบอาร์เรย์
การนำข้อมูลเข้าสู่โครงสร้างคิว (enqueue)
เป็นกระบวนการอ่านข้อมูลจากภายนอกเข้าสู่โครงสร้างคิวทางด้านปลายที่พอยน์เตอร์ R
ชี้อยู่ โดยพอยน์เตอร์ R จะเปลี่ยนตำแหน่ง ชี้ไปยังตำแหน่งที่ว่างตำแหน่งถัดไป
ก่อนนำข้อมูลเข้าสู่โครงสร้างคิวข้อควรคำนึงถึง คือ ในขณะที่คิวเต็ม (Full Queues)
หรือไม่มีช่องว่างเหลืออยู่ จะไม่สามารถนำข้อมูลเข้าไปเก็บในโครงสร้างคิวได้อีก
ซึ่งจะทำให้เกิดปัญหา “Overflow” ขึ้น
1.) Create Queue
เป็นการจัดสรรหน่วยความจำให้กับ Head Node และให้ค่า pointer ทั้ง 2 ตัวมีค่าป็น null และจำนวนสมาชิกเป็นศูนย์
2.) Enqueue
เป็นการเพิ่มข้อมูลเข้าไปในคิว ซึ่ง pointer rear จะเปลี่ยน
3.) Dequeue
เป็นการนำข้อมูลออกจากคิว ซึ่ง pointer front จะเปลี่ยน
4.) Queue Front
เป็นการนำข้อมูลที่อยู่ตอนต้นของคิวมาแสดง
5.) Queue Rear
เป็นการนำข้อมูลที่อยู่ส่วนท้ายของคิวมาแสดง
6.) Empty Queue
เป็นการตรวจสอบว่าคิวว่างหรือไม่
7.) Full Queue
เป็นการตรวจสอบว่าคิวเต็มหรือไม่
8.) Queue Count
เป็นการนับจำนวนสมาชิกที่อยู่ในคิว
9.) Destroy Queue
เป็นการลบข้อมูลทั้งหมดที่อยู่ในคิว วิธีการคือ ต้องทำการ Dequeue ทีละตัว แล้วจึงจะ Destroy
วันอังคารที่ 4 สิงหาคม พ.ศ. 2552
DTS 06-30-06-2552
stack (ต่อ)
การเเทนที่ข้อมูลของสเเตกแบบอะเรย์การดำเนินงานเกี่ยวกับสแตก ได้แก่
1.Creste stackคือ สร้าง stack head node
2.Push stackคือ เพิ่มรายการใน stack
3.Pop stackคือ ลบรายการใน stack
4.Stack topคือ เรียกใช้งานรายการข้อมูลที่อยู่บนสุดของ stack
5.Empty stackคือ ตรวจสอบว่า stack ว่างเปล่าหรือไม่
6.Full stackคือ ตรวจสอบว่า stack เต็มหรือไม่
7.Stack countคือ ส่งค่าจำนวนรายการใน stack
8.Destroy stackคือ การคืนหน่วยความจำของทุก node ใน stack ให้ระบบ
ลำดับการทำงานของตัวดำเนินการทางคณิตศาสตร์ (Operator Priority)
มีการลำดับความสำคัญของตัวดำเนินการจากลำดับสำคัญมากสุดไปน้อยสุด
คือ ลำดับที่มีความสำคัญมากที่ต้องทำก่อน ไปจนถึงลำดับที่มีความสำคัญน้อยสุดที่ไว้ทำทีหลัง ดังนี้
1. ทำในเครื่องหมายวงเล็บ
2. เครื่องหมายยกกำลัง ( ^ )
3. เครื่องหมายคูณ ( * ) , หาร ( / )
4. เครื่องหมายบวก ( + ) , ลบ ( - )
การใช้ สแตค เพื่อแปลรูปนิพจน์ทางคณิตศาสตร์รูปแบบนิพจน์ทางคณิตศาสตร์
• นิพจน์ Infix คือ นิพจน์ที่เครื่องหมายดำเนินการ (Operator)
อยู่ระหว่างตัวดำเนินการ (Operands) เช่น A+B-C
• นิพจน์ Postfix คือ นิพจน์ที่เครื่องหมายดำเนินการ (Operator)
อยู่หลังตัวดำเนินการ (Operands) เช่น AC*+
การแปลงนิพจน์ Infix เป็น นิพจน์ Postfix
เราสามารถแปลงนิพจน์ Infix ให้เป็น Postfix ได้โดยอาศัยสแตค
ที่มีคุณสมบัติการเข้าหลังออกก่อนหรือ LIFO โดยมีอัลกอริทึมในการแปลงนิพจน์ ดังนี้
1. ถ้าข้อมูลเข้า (input) เป็นตัวถูกดำเนินการ (operand) ให้นำออกไปเป็นผลลัพธ์ (output)
2. ถ้าข้อมูลเข้าเป็นตัวดำเนินการ (operator) ให้ดำเนินการดังนี้
2.1 ถ้าสแตคว่าง ให้ push operator ลงในสแตค
2.2 ถ้าสแตคไม่ว่าง ให้เปรียบเทียบ operator ที่เข้ามากับ operator ที่อยู่ในตำแหน่ง TOP ของสแตค
2.2.1 ถ้า operator ที่เข้ามามีความสำคัญมากกว่า operator ที่ตำแหน่ง TOP ของสแตคให้ pusสแตค
2.2.2 ถ้า operator ที่เข้ามามีความสำคัญน้อยกว่าหรือเท่ากับ operator ที่อยู่ในตำแหน่ง TOP
ของสแตค ให้ pop สแตคออกไปเป็นผลลัพธ์ แล้วทำการเปรียบเทียบ operator
ที่เข้ามากับ operator ที่ตำแหน่ง TOP ต่อไป จะหยุดจนกว่า operator ที่เข้ามา
จะมีความสำคัญมากกว่า operator ที่ตำแหน่ง TOP ของสแตค แล้วจึง push operator
ที่เข้ามานั้นลงสแตค
3. ถ้าข้อมูลเข้าเป็นวงเล็บเปิด ให้ push ลงสแตค
4. ถ้าข้อมูลเข้าเป็นวงเล็บปิด ให้ pop ข้อมูลออกจากสแตคไปเป็นผลลัพธ์
จนกว่าจะถึงวงเล็บ เปิด จากนั้นทิ้งวงเล็บเปิดและปิดทิ้งไป
5. ถ้าข้อมูลเข้าหมด ให้ pop ข้อมูลออกจากสแตคไปเป็นผลลัพธ์จนกว่าสแตคจะว่าง
การเเทนที่ข้อมูลของสเเตกแบบอะเรย์การดำเนินงานเกี่ยวกับสแตก ได้แก่
1.Creste stackคือ สร้าง stack head node
2.Push stackคือ เพิ่มรายการใน stack
3.Pop stackคือ ลบรายการใน stack
4.Stack topคือ เรียกใช้งานรายการข้อมูลที่อยู่บนสุดของ stack
5.Empty stackคือ ตรวจสอบว่า stack ว่างเปล่าหรือไม่
6.Full stackคือ ตรวจสอบว่า stack เต็มหรือไม่
7.Stack countคือ ส่งค่าจำนวนรายการใน stack
8.Destroy stackคือ การคืนหน่วยความจำของทุก node ใน stack ให้ระบบ
ลำดับการทำงานของตัวดำเนินการทางคณิตศาสตร์ (Operator Priority)
มีการลำดับความสำคัญของตัวดำเนินการจากลำดับสำคัญมากสุดไปน้อยสุด
คือ ลำดับที่มีความสำคัญมากที่ต้องทำก่อน ไปจนถึงลำดับที่มีความสำคัญน้อยสุดที่ไว้ทำทีหลัง ดังนี้
1. ทำในเครื่องหมายวงเล็บ
2. เครื่องหมายยกกำลัง ( ^ )
3. เครื่องหมายคูณ ( * ) , หาร ( / )
4. เครื่องหมายบวก ( + ) , ลบ ( - )
การใช้ สแตค เพื่อแปลรูปนิพจน์ทางคณิตศาสตร์รูปแบบนิพจน์ทางคณิตศาสตร์
• นิพจน์ Infix คือ นิพจน์ที่เครื่องหมายดำเนินการ (Operator)
อยู่ระหว่างตัวดำเนินการ (Operands) เช่น A+B-C
• นิพจน์ Postfix คือ นิพจน์ที่เครื่องหมายดำเนินการ (Operator)
อยู่หลังตัวดำเนินการ (Operands) เช่น AC*+
การแปลงนิพจน์ Infix เป็น นิพจน์ Postfix
เราสามารถแปลงนิพจน์ Infix ให้เป็น Postfix ได้โดยอาศัยสแตค
ที่มีคุณสมบัติการเข้าหลังออกก่อนหรือ LIFO โดยมีอัลกอริทึมในการแปลงนิพจน์ ดังนี้
1. ถ้าข้อมูลเข้า (input) เป็นตัวถูกดำเนินการ (operand) ให้นำออกไปเป็นผลลัพธ์ (output)
2. ถ้าข้อมูลเข้าเป็นตัวดำเนินการ (operator) ให้ดำเนินการดังนี้
2.1 ถ้าสแตคว่าง ให้ push operator ลงในสแตค
2.2 ถ้าสแตคไม่ว่าง ให้เปรียบเทียบ operator ที่เข้ามากับ operator ที่อยู่ในตำแหน่ง TOP ของสแตค
2.2.1 ถ้า operator ที่เข้ามามีความสำคัญมากกว่า operator ที่ตำแหน่ง TOP ของสแตคให้ pusสแตค
2.2.2 ถ้า operator ที่เข้ามามีความสำคัญน้อยกว่าหรือเท่ากับ operator ที่อยู่ในตำแหน่ง TOP
ของสแตค ให้ pop สแตคออกไปเป็นผลลัพธ์ แล้วทำการเปรียบเทียบ operator
ที่เข้ามากับ operator ที่ตำแหน่ง TOP ต่อไป จะหยุดจนกว่า operator ที่เข้ามา
จะมีความสำคัญมากกว่า operator ที่ตำแหน่ง TOP ของสแตค แล้วจึง push operator
ที่เข้ามานั้นลงสแตค
3. ถ้าข้อมูลเข้าเป็นวงเล็บเปิด ให้ push ลงสแตค
4. ถ้าข้อมูลเข้าเป็นวงเล็บปิด ให้ pop ข้อมูลออกจากสแตคไปเป็นผลลัพธ์
จนกว่าจะถึงวงเล็บ เปิด จากนั้นทิ้งวงเล็บเปิดและปิดทิ้งไป
5. ถ้าข้อมูลเข้าหมด ให้ pop ข้อมูลออกจากสแตคไปเป็นผลลัพธ์จนกว่าสแตคจะว่าง
วันอังคารที่ 28 กรกฎาคม พ.ศ. 2552
DTS 05-23-07-2552
สรุป โครงสร้างข้อมูล เรื่อง Linked list และ Stack
การลบข้อมูลใน Linked list
เนื่องจากขั้นตอนของการลบข้อมูลที่ header นั้นจะมีปัญหาที่ยุ่งยากกว่าเมื่อ design ด้วย oop(java)
เราสามารถที่จะแก้ปัญหานี้ได้โดยการใส่ header node ที่ว่าง ๆ ไว้ข้างหน้าของ linked list
เพื่อที่จะทำหน้าที่เป็นชี้ว่าเป็นหัวโหนดโดยที่ไม่ต้องมี pointerคอยชี้ที่ header และเมื่อเราต้องการที่จะเปลี่ยนแปลงข้อมูลใด ๆ บนหัวสามารถที่จะทำได้โดยการแทรก node เข้าไป
กระบวนงาน Search list
หน้าที่ :ค้นหาข้อมูลในลิสต์ที่ต้องการข้อมูลนำเข้าลิสต์
ผลลัพธ์ :ค่าจริงถ้าพบข้อมูล ค่าเท็จถ้าไม่พบข้อมูล
กระบวนงาน Traverse
หน้าที่:ท่องไปในลิสต์เพื่อเข้าถึงและประมวลผลข้อมูล นำเข้าลิสต ผลลัพธ์ ขึ้นกับการประมวลผล
เช่นเปลี่ยนแปลงค่าใน nodeรวมฟิลด์ในลิสต์ ,คำนวณค่าเฉลี่ยของฟิลด์ เป็นต้น
กระบวนงาน Retrieve Node
หน้าที่ :หาตำแหน่งข้อมูลจากลิสต์ข้อมูลนำเข้าลิสต์ผลลัพธ์ ตำแหน่งข้อมูลที่อยู่ในลิสต์
ฟังก์ชั่น EmptyList
หน้าที่ :ทดสอบว่าลิสต์ว่างข้อมูลนำเข้า ลิสต์ผลลัพธ์ เป็นจริง ถ้าลิสต์ว่าเป็นเท็จ ถ้าลิสต์ไม่ว่าง
ฟังก์ชั่น FullList
หน้าที่:ทดสอบว่าลิสต์เต็มหรือไม่ข้อมูล นำเข้าลิสต์ผลลัพธ์ เป็นจริง ถ้าหน่วยความจำเต็ม
เป็นเท็จ ถ้าสามารถมีโหนดอื่น
ฟังก์ชั่น list count
หน้าที่ :นับจำนวนข้อมูลที่อยู่ในลิสต์ข้อมูลนำเข้าลิสต์ผลลัพธ์ จำนวนข้อมูลที่อยู่ในลิสต์
กระบวนงาน destroy list
หน้าที่:ทำลายลิสต์ข้อมูลนำเข้า ลิสต์ผลลัพธ์ ไม่มีลิสต์
stack
คือ โครงสร้างข้อมูลที่สำคัญและมีลักษณะเรียบง่ายซึ่งใช้แถวลำดับเป็นโครงสร้างสำหรับเก็บข้อมูลพื้นฐานได้แก่สแตก เพราะภาษาคอมพิวเตอร์ส่วนมากกำหนดชนิดแถวลำดับไว้ล่วงหน้าและการทำงานของแถวลำดับสะดวกและเรียบง่าย สแตกเป็นโครงสร้างข้อมูลแบบลิเนียร์ลิสต์(linear list) ที่สามารถนำข้อมูลเข้าหรือออกได้ทางเดียวคือส่วนบนของสแตกหรือ หรือเรียกว่า ท๊อปของสแตก (Top Of Stack) ซึ่งคุณสมบัติดังกล่าวเรียกว่า ไลโฟลิสต์ (LIFO list: Last-In-First-Out list) หรือ พูชดาวน์ลิสต์ (Pushdown List) คือสมาชิกที่เข้าลิสต์ที่หลังสุดจะได้ออกจากลิสต์ก่อน หรือ เข้าหลังออกก่อน การเพิ่มข้อมูลเข้าสแตกจะเรียกว่าพูชชิ่ง (pushing) การนำข้อมูลจากสแตกเรียกว่า ป๊อปปิ้ง (poping) การเพิ่มหรือลบข้อมูลในสแตกทำที่ท๊อปของสแตก ท๊อปของสแตกนี้เองเป็นตัวชี้สมาชิกตัวท้ายสุดของสแตก
Popping Stack
หมายถึงการเอาข้อมูลที่อยู่บนสุดในสแตก หรือที่ชี้ด้วยท๊อปออกจากสแตก เรียกว่าการ pop ในการpop นั้นเราจะสามารถ pop ข้อมูลจากสแตกได้เรื่อย ๆ จนกว่า ข้อมูลจะหมดสแตก หรือ เป็นสแตกว่าง โดยก่อนที่จะนำข้อมูลออกจากสแตก จะต้องมีการตรวจสอบว่าใน สแตกมีข้อมูลเก็บ อยู่หรือไม่
Stack Top
เป็นการคัดลอกข้อมูลที่อยู่บนสุดของสแตก แต่ไม่ได้นำเอาข้อมูลนั้นออกจากสแตก
ตัวอย่างการทำงานแบบโครงสร้างข้อมูลแบบสแตก
ไดแก่ รถขนรถยนต์ คือ เวลานำรถ(ใหม่)ขึ้นไปบนรถขนรถ จะต้องนำ(ใหม่)คันเเรกขึ้นไปก่อน
เเต่พอเวลานำ(ใหม่)ออก ต้องนำ(ใหม่)คันที่เข้าที่หลังออกก่อน
การลบข้อมูลใน Linked list
เนื่องจากขั้นตอนของการลบข้อมูลที่ header นั้นจะมีปัญหาที่ยุ่งยากกว่าเมื่อ design ด้วย oop(java)
เราสามารถที่จะแก้ปัญหานี้ได้โดยการใส่ header node ที่ว่าง ๆ ไว้ข้างหน้าของ linked list
เพื่อที่จะทำหน้าที่เป็นชี้ว่าเป็นหัวโหนดโดยที่ไม่ต้องมี pointerคอยชี้ที่ header และเมื่อเราต้องการที่จะเปลี่ยนแปลงข้อมูลใด ๆ บนหัวสามารถที่จะทำได้โดยการแทรก node เข้าไป
กระบวนงาน Search list
หน้าที่ :ค้นหาข้อมูลในลิสต์ที่ต้องการข้อมูลนำเข้าลิสต์
ผลลัพธ์ :ค่าจริงถ้าพบข้อมูล ค่าเท็จถ้าไม่พบข้อมูล
กระบวนงาน Traverse
หน้าที่:ท่องไปในลิสต์เพื่อเข้าถึงและประมวลผลข้อมูล นำเข้าลิสต ผลลัพธ์ ขึ้นกับการประมวลผล
เช่นเปลี่ยนแปลงค่าใน nodeรวมฟิลด์ในลิสต์ ,คำนวณค่าเฉลี่ยของฟิลด์ เป็นต้น
กระบวนงาน Retrieve Node
หน้าที่ :หาตำแหน่งข้อมูลจากลิสต์ข้อมูลนำเข้าลิสต์ผลลัพธ์ ตำแหน่งข้อมูลที่อยู่ในลิสต์
ฟังก์ชั่น EmptyList
หน้าที่ :ทดสอบว่าลิสต์ว่างข้อมูลนำเข้า ลิสต์ผลลัพธ์ เป็นจริง ถ้าลิสต์ว่าเป็นเท็จ ถ้าลิสต์ไม่ว่าง
ฟังก์ชั่น FullList
หน้าที่:ทดสอบว่าลิสต์เต็มหรือไม่ข้อมูล นำเข้าลิสต์ผลลัพธ์ เป็นจริง ถ้าหน่วยความจำเต็ม
เป็นเท็จ ถ้าสามารถมีโหนดอื่น
ฟังก์ชั่น list count
หน้าที่ :นับจำนวนข้อมูลที่อยู่ในลิสต์ข้อมูลนำเข้าลิสต์ผลลัพธ์ จำนวนข้อมูลที่อยู่ในลิสต์
กระบวนงาน destroy list
หน้าที่:ทำลายลิสต์ข้อมูลนำเข้า ลิสต์ผลลัพธ์ ไม่มีลิสต์
stack
คือ โครงสร้างข้อมูลที่สำคัญและมีลักษณะเรียบง่ายซึ่งใช้แถวลำดับเป็นโครงสร้างสำหรับเก็บข้อมูลพื้นฐานได้แก่สแตก เพราะภาษาคอมพิวเตอร์ส่วนมากกำหนดชนิดแถวลำดับไว้ล่วงหน้าและการทำงานของแถวลำดับสะดวกและเรียบง่าย สแตกเป็นโครงสร้างข้อมูลแบบลิเนียร์ลิสต์(linear list) ที่สามารถนำข้อมูลเข้าหรือออกได้ทางเดียวคือส่วนบนของสแตกหรือ หรือเรียกว่า ท๊อปของสแตก (Top Of Stack) ซึ่งคุณสมบัติดังกล่าวเรียกว่า ไลโฟลิสต์ (LIFO list: Last-In-First-Out list) หรือ พูชดาวน์ลิสต์ (Pushdown List) คือสมาชิกที่เข้าลิสต์ที่หลังสุดจะได้ออกจากลิสต์ก่อน หรือ เข้าหลังออกก่อน การเพิ่มข้อมูลเข้าสแตกจะเรียกว่าพูชชิ่ง (pushing) การนำข้อมูลจากสแตกเรียกว่า ป๊อปปิ้ง (poping) การเพิ่มหรือลบข้อมูลในสแตกทำที่ท๊อปของสแตก ท๊อปของสแตกนี้เองเป็นตัวชี้สมาชิกตัวท้ายสุดของสแตก
Popping Stack
หมายถึงการเอาข้อมูลที่อยู่บนสุดในสแตก หรือที่ชี้ด้วยท๊อปออกจากสแตก เรียกว่าการ pop ในการpop นั้นเราจะสามารถ pop ข้อมูลจากสแตกได้เรื่อย ๆ จนกว่า ข้อมูลจะหมดสแตก หรือ เป็นสแตกว่าง โดยก่อนที่จะนำข้อมูลออกจากสแตก จะต้องมีการตรวจสอบว่าใน สแตกมีข้อมูลเก็บ อยู่หรือไม่
Stack Top
เป็นการคัดลอกข้อมูลที่อยู่บนสุดของสแตก แต่ไม่ได้นำเอาข้อมูลนั้นออกจากสแตก
ตัวอย่างการทำงานแบบโครงสร้างข้อมูลแบบสแตก
ไดแก่ รถขนรถยนต์ คือ เวลานำรถ(ใหม่)ขึ้นไปบนรถขนรถ จะต้องนำ(ใหม่)คันเเรกขึ้นไปก่อน
เเต่พอเวลานำ(ใหม่)ออก ต้องนำ(ใหม่)คันที่เข้าที่หลังออกก่อน


วันจันทร์ที่ 20 กรกฎาคม พ.ศ. 2552
DTS 04-15-07-2552
สรุปเนื้อหาบทเรียน "Data Structure"
เรื่อง Linked List
โครงสร้างข้อมูลแบบลิงค์ลิสต์จะแบ่งเป็น 2 ส่วน คือ
1. Head Structure จะประกอบไปด้วย 3 ส่วน
 เพิ่มข้อมูล 5 เข้าไปใน list , L ชี้ไปยังโหนดที่เก็บข้อมูล
เพิ่มข้อมูล 5 เข้าไปใน list , L ชี้ไปยังโหนดที่เก็บข้อมูล
 เพิ่มข้อมูล 14 เข้าไปใน list , L ชี้ไปยังโหนดที่เก็บ
เพิ่มข้อมูล 14 เข้าไปใน list , L ชี้ไปยังโหนดที่เก็บ

การเพิ่มและลบข้อมูลใน Linked list
เรื่อง Linked List
Linked List
ลิงค์ลิสต์เป็นการจัดเก็บชุดข้อมูลเชื่อมโยงต่อเนื่องกันไปตามลำดับ
ซึ่งอาจอยู่ในลักษณะแบบเชิงเส้นตรง (linear) หรือ ไม่เป็นเส้นตรง (nonlinear) ก็ได้
ซึ่งในลิสต์จะประกอบไปด้วยข้อมูลที่เรียกว่าโหนด (node)
ในหนึ่งโหนดจะประกอบด้วยส่วนของข้อมูลที่ต้องการจัดเก็บ
เรียกว่าส่วน Info และส่วนที่เป็นพอยน์เตอร์ที่ชี้ไปยังโหนดถัดไป (Link)
หรือชี้ไปยังโหนดอื่นๆที่อยู่ในลิสต์ หากไม่มีโหนดที่อยู่ถัดไป
ส่วนที่เป็นพอยน์เตอร์หรือ Link จะเก็บค่า NULL หรือสัญลักษณ์ ^
โครงสร้างข้อมูลแบบลิงค์ลิสต์จะแบ่งเป็น 2 ส่วน คือ
1. Head Structure จะประกอบไปด้วย 3 ส่วน
ได้แก่ จำนวนโหนดในลิสต์ (Count)
พอยเตอร์ที่ชี้ไปยัง โหนดที่เข้าถึง (Pos)
และพอยเตอร์ที่ชี้ไปยังโหนดข้อมูล แรกของลิสต์ (Head)
2. Data Node Structure จะประกอบไปด้วยข้อมูล
(Data) และพอยเตอร์ที่ชี้ไปยังข้อมูลตัวถัดไป
(Data) และพอยเตอร์ที่ชี้ไปยังข้อมูลตัวถัดไป
การสร้าง Linked list
วิธีสร้าง Linked list คือการนำข้อมูลที่จะจัดเก็บเข้า Linked list
วิธีสร้าง Linked list คือการนำข้อมูลที่จะจัดเก็บเข้า Linked list
เพิ่มตรงโหนดตำแหน่งสุดท้ายของลิสต์ ฉะนั้นจึงต้องมี External พอยน์เตอร์
ที่คอยชี้โหนดสุดท้ายของลิสต์ ในที่นี้ใช้ L (Last)
ตัวอย่างการสร้าง Linked list จากลิสต์ L = 21 , 5 , 14
เริ่มจากการให้ H ชี้ทิ่โหนดตำแหน่งแรก และ L ชี้ทิ่โหนดตำแหน่งสุดท้าย
 เพิ่มข้อมูล 5 เข้าไปใน list , L ชี้ไปยังโหนดที่เก็บข้อมูล
เพิ่มข้อมูล 5 เข้าไปใน list , L ชี้ไปยังโหนดที่เก็บข้อมูล  เพิ่มข้อมูล 14 เข้าไปใน list , L ชี้ไปยังโหนดที่เก็บ
เพิ่มข้อมูล 14 เข้าไปใน list , L ชี้ไปยังโหนดที่เก็บ
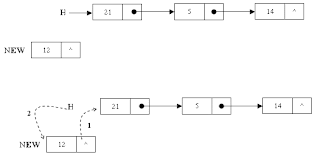
การเพิ่มและลบข้อมูลใน Linked list

จากรูป จะเพิ่ม NODE(tmp) ลงใน linked list โดยมีขั้นตอนคือ
tmp = new ListNode();
tmp = new ListNode();
tmp.element = 12;
tmp.next = current.next;
วันอาทิตย์ที่ 12 กรกฎาคม พ.ศ. 2552
DTS 03-01-07-2552
สรุปเนื้อหาบทเรียน "Data Structure"
เรื่อง Pointer , set and string
Pointer คือตัวแปรที่ทำหน้าที่เก็บตำแหน่งที่อยู่ของตัวแปรที่อยู่ในหน่วยความจำ
การประกาศชนิดของตัวเเปรพอยน์เตอร์
รูปแบบจะเป็น
type *variable-name
ต้องมีระบุตัวดำเนินการ เพื่อบอกว่าตัวแปรดังกล่าวเป็นตัวแปรแบบตัวชี้
โดยตัวดำเนินการที่ใช้คือ
1. เครื่องหมาย &
เป็นเครื่องหมายที่ใช้เมื่อต้องการให้เอาค่าตำแหน่งที่อยู่ของตัวแปร
ที่เก็บไว้ในหน่วยความจำออกมาใช้
เช่น m = &count;
เป็นการนำตำแหน่งในหน่วยความจำของตัวแปร count ใส่ลงไปในตัวแปร (แบบพอยท์เตอร์)
m ซึ่งตำแหน่งที่ว่านี้เป็นตำแหน่งของตัวแปรนั้น ๆ ภายในของคอมพิวเตอร์
2. เครื่องหมาย *
ซึ่งจะมีการใช้งานอยู่ 2 ลักษณะ
- ใช้ในการประกาศ parameter
เช่น void swap(int*p,int*q)
{
............................
}
- ใช้เป็น dereferencing operator จะใช้เมื่อต้องการนำค่าที่อยู่ในตำแหน่ง
ที่ตัวแปรพอยน์เตอร์นั้นชี้อยู่ออกมาแสดง
set and string
โครงสร้างข้อมูลแบบสตตริงสตริง หรือ สตริงของอักขระ
เป็นข้อมูลที่ประกอบบไปด้วย ตัวอักษร ตัวเลขหรือเครื่องหมายเรียงติดต่อกันไป
รวมทั้งช่องว่างการประยุกต์ใช้คอมพิวเตอร์ที่เกี่ยวกับข้อมูลที่เป็นสตริง
มีการนำไปใช้สร้างโปรแกรมประเภทบรรณาธิการข้อความ หรือโปรแกรมประเภทประมวลคำ
ซึ่งมีการทำงานที่อำนวยความสะดวกหลายอย่าง
เช่น การตรวจสอบข้อความ การจัดแนวข้อความ ในแต่ละย่อหน้า และการค้นหาคำ เป็นต้น
เช่น "UNIVERSITY!" จะเป็นข้อมูลแบบสตริงยาว 10 อักขระสตริงกับอะแรย์สตริง
คือ อะเรย์ของอักขระ เช่น char a[5]อาจจะเป็นอะเรย์ขนาด 6 ช่องอักขระ
หรือ เป็นสตริงขนาด 5 อักขระก้อได้
โดยจุดสิ้นสุดของ string จะจบด้วย \0 หรือ null character
เช่นchar a[]={'H','E','L','L','O','\0'};char a[]="hello";
เรื่อง Pointer , set and string
Pointer คือตัวแปรที่ทำหน้าที่เก็บตำแหน่งที่อยู่ของตัวแปรที่อยู่ในหน่วยความจำ
การประกาศชนิดของตัวเเปรพอยน์เตอร์
รูปแบบจะเป็น
type *variable-name
ต้องมีระบุตัวดำเนินการ เพื่อบอกว่าตัวแปรดังกล่าวเป็นตัวแปรแบบตัวชี้
โดยตัวดำเนินการที่ใช้คือ
1. เครื่องหมาย &
เป็นเครื่องหมายที่ใช้เมื่อต้องการให้เอาค่าตำแหน่งที่อยู่ของตัวแปร
ที่เก็บไว้ในหน่วยความจำออกมาใช้
เช่น m = &count;
เป็นการนำตำแหน่งในหน่วยความจำของตัวแปร count ใส่ลงไปในตัวแปร (แบบพอยท์เตอร์)
m ซึ่งตำแหน่งที่ว่านี้เป็นตำแหน่งของตัวแปรนั้น ๆ ภายในของคอมพิวเตอร์
2. เครื่องหมาย *
ซึ่งจะมีการใช้งานอยู่ 2 ลักษณะ
- ใช้ในการประกาศ parameter
เช่น void swap(int*p,int*q)
{
............................
}
- ใช้เป็น dereferencing operator จะใช้เมื่อต้องการนำค่าที่อยู่ในตำแหน่ง
ที่ตัวแปรพอยน์เตอร์นั้นชี้อยู่ออกมาแสดง
set and string
โครงสร้างข้อมูลแบบสตตริงสตริง หรือ สตริงของอักขระ
เป็นข้อมูลที่ประกอบบไปด้วย ตัวอักษร ตัวเลขหรือเครื่องหมายเรียงติดต่อกันไป
รวมทั้งช่องว่างการประยุกต์ใช้คอมพิวเตอร์ที่เกี่ยวกับข้อมูลที่เป็นสตริง
มีการนำไปใช้สร้างโปรแกรมประเภทบรรณาธิการข้อความ หรือโปรแกรมประเภทประมวลคำ
ซึ่งมีการทำงานที่อำนวยความสะดวกหลายอย่าง
เช่น การตรวจสอบข้อความ การจัดแนวข้อความ ในแต่ละย่อหน้า และการค้นหาคำ เป็นต้น
เช่น "UNIVERSITY!" จะเป็นข้อมูลแบบสตริงยาว 10 อักขระสตริงกับอะแรย์สตริง
คือ อะเรย์ของอักขระ เช่น char a[5]อาจจะเป็นอะเรย์ขนาด 6 ช่องอักขระ
หรือ เป็นสตริงขนาด 5 อักขระก้อได้
โดยจุดสิ้นสุดของ string จะจบด้วย \0 หรือ null character
เช่นchar a[]={'H','E','L','L','O','\0'};char a[]="hello";
วันอังคารที่ 30 มิถุนายน พ.ศ. 2552
วันอาทิตย์ที่ 28 มิถุนายน พ.ศ. 2552
การบ้าน "Structure"
#include
#include
void main (){
struct address{
char village[20];
char city[20];
char country[20];
};
struct student{
char name[30];
char surname[20];
char phone_num[15];
int age;
float grade;
char name_of_university[50];
char name_of_faculty[50];
struct address address1;
}student1;
strcpy(student1.name,"Kanyavee");
strcpy(student1.surname,"Kornvasurom");
student1.age=20;
strcpy(student1.address1.village,"Buathong");
strcpy(student1.address1.city,"Nonthaburi");
strcpy(student1.address1.country,"Thailand");
strcpy(student1.phone_num,"0867751413");
student1.grade=2.37;
strcpy(student1.name_of_university,"SDU");
strcpy(student1.name_of_faculty,"Business_computer");
printf("name:%s\n\n",student1.name);
printf("surname:%s\n\n",student1.surname);
printf("phone_num:%s\n\n",student1.phone_num);
printf("age:%d\n\n",student1.age);
printf("village:%s\n\n",student1.address1.village);
printf("city:%s\n\n",student1.address1.city);
printf("country:%s\n\n",student1.address1.country);
printf("grade:%.2f\n\n",student1.grade);
printf("name_of_university:%s\n\n",student1.name_of_university);
printf("name_of_faculty:%s\n\n",student1.name_of_faculty);
}
#include
void main (){
struct address{
char village[20];
char city[20];
char country[20];
};
struct student{
char name[30];
char surname[20];
char phone_num[15];
int age;
float grade;
char name_of_university[50];
char name_of_faculty[50];
struct address address1;
}student1;
strcpy(student1.name,"Kanyavee");
strcpy(student1.surname,"Kornvasurom");
student1.age=20;
strcpy(student1.address1.village,"Buathong");
strcpy(student1.address1.city,"Nonthaburi");
strcpy(student1.address1.country,"Thailand");
strcpy(student1.phone_num,"0867751413");
student1.grade=2.37;
strcpy(student1.name_of_university,"SDU");
strcpy(student1.name_of_faculty,"Business_computer");
printf("name:%s\n\n",student1.name);
printf("surname:%s\n\n",student1.surname);
printf("phone_num:%s\n\n",student1.phone_num);
printf("age:%d\n\n",student1.age);
printf("village:%s\n\n",student1.address1.village);
printf("city:%s\n\n",student1.address1.city);
printf("country:%s\n\n",student1.address1.country);
printf("grade:%.2f\n\n",student1.grade);
printf("name_of_university:%s\n\n",student1.name_of_university);
printf("name_of_faculty:%s\n\n",student1.name_of_faculty);
}
DTS 02-24-06-2552
สรุปเนื้อหาบทเรียน "Data Structure"
เรื่อง Array and Record.
การกำหนดค่า อะเรย์ ถ้าอะเรย์ที่มี subscript มากกว่า 1ตัวขึ้นไป เรียกว่า "อะเรย์หลายมิติ"
การกำหนดค่าต่ำสุดเเละสูงสุดของ subscript คือ ค่าต่ำสุดต้องมีค่าน้อยกว่าหรือเท่ากับค่าสูงสุดเสมอ
- ค่าต่ำสุดจะเรียกว่า "ขอบเขตล่าง"
- ค่าสูงสุดจะเรียกว่า "ขอบเขตบน"
การกำหนดค่าให้กับตัวแปรชนิด character ตัวสุดท้ายจะเก็บค่า "\0" โดยอัตโนมัติ
เพื่อสิ้นสุดข้อความ ส่วน อะเรย์หลายมิติ จะเเตกต่างกันที่ จะมีตัวห้อยของแถวเเละคอลัมน์ต่างกัน
ส่วน Structure จะหมายถึง
โครงสร้างที่สมาชิกแต่ละตัวมีประเภทข้อมูลแตกต่างกันได้
อาจจะมีสมาชิกเป็นจำนาวนเต็ม ทศนิยม อักขระ อะเรย์หรือ พอยเตอร์ ด้วยกันได้
การกำนดให้ตัวแปรมีโครงสร้างข้อมูลเหมือนกัน Structure ที่ประกาศไว้เเล้วจะใช้คำสั่ง Struct
ถ้ามีหลายตัวแปรจะคั่นด้วยเครื่องหมาย "คอมม่า" (,)
เช่น Struct employee emp1 , emp2 เป็นต้น
เรื่อง Array and Record.
การกำหนดค่า อะเรย์ ถ้าอะเรย์ที่มี subscript มากกว่า 1ตัวขึ้นไป เรียกว่า "อะเรย์หลายมิติ"
การกำหนดค่าต่ำสุดเเละสูงสุดของ subscript คือ ค่าต่ำสุดต้องมีค่าน้อยกว่าหรือเท่ากับค่าสูงสุดเสมอ
- ค่าต่ำสุดจะเรียกว่า "ขอบเขตล่าง"
- ค่าสูงสุดจะเรียกว่า "ขอบเขตบน"
การกำหนดค่าให้กับตัวแปรชนิด character ตัวสุดท้ายจะเก็บค่า "\0" โดยอัตโนมัติ
เพื่อสิ้นสุดข้อความ ส่วน อะเรย์หลายมิติ จะเเตกต่างกันที่ จะมีตัวห้อยของแถวเเละคอลัมน์ต่างกัน
ส่วน Structure จะหมายถึง
โครงสร้างที่สมาชิกแต่ละตัวมีประเภทข้อมูลแตกต่างกันได้
อาจจะมีสมาชิกเป็นจำนาวนเต็ม ทศนิยม อักขระ อะเรย์หรือ พอยเตอร์ ด้วยกันได้
การกำนดให้ตัวแปรมีโครงสร้างข้อมูลเหมือนกัน Structure ที่ประกาศไว้เเล้วจะใช้คำสั่ง Struct
ถ้ามีหลายตัวแปรจะคั่นด้วยเครื่องหมาย "คอมม่า" (,)
เช่น Struct employee emp1 , emp2 เป็นต้น
ประวัติส่วนตัว

ชื่อ นางสาวกันยาวีร์ กรวสุรมย์
ชื่อเล่น "มิ้นท์"
วันเกิด 06 พฤษภาคม 2532
อายุ 20 ปี
ที่อยู่ 118/281 หมู่บ้านบัวทอง ซอย10/7 ถนนตลิ่งชัน-สุพรรณ
บางรักพัฒนา บางบัวทอง นนทบุรี 11110
เบอร์โทรศัพท์ 0867751413
คติพจน์ ฐานของบ้านคืออิฐ ฐานของชีวิตคือการศึกษา
E-mail snap_okey@hotmail.com
กำลังศึกษาอยู่ที่ มหาวิทยาลัยราชภัฏสวนดุสิต
คณะ วิทยาการจัดการ
หลักสูตร การบริหารธุรกิจ (คอมพิวเตอร์ธุรกิจ)

{kind=link}